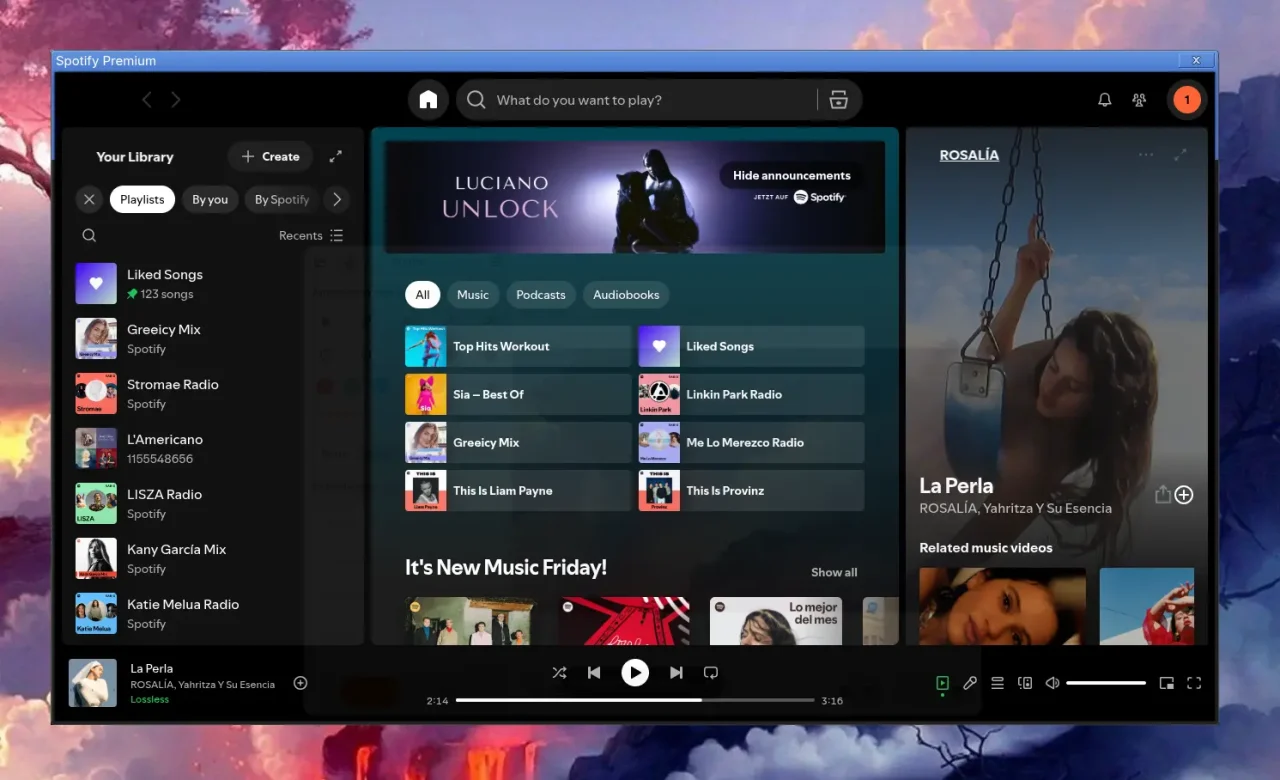
Wenn ihr Spotify unter Linux mit GNOME nutzt, habt ihr vielleicht in den letzten Tagen einen unschönen blauen Rahmen um das Anwendungsfenster bemerkt. Ich sehe das Problem hier bei mir unter Arch Linux, es dürfte aber alle Distributionen betreffen.
Schuld daran ist ein Update des offiziellen Linux-Clients auf Electron-Basis, das die GTK-Style-Window-Decoration durcheinandergebracht hat. Die Funktionalität von Spotify bleibt zwar unverändert, optisch sieht es aber alles andere als schick aus.
Spotify mit blauem Rahmen. Ein Update des Linux-Clients hat die GTK-Style-Window-Decoration beschädigt, sodass das Fenster unschön blau gerahmt wird und nicht korrekt angezeigt wird.
Lösungsmöglichkeiten für Spotify
Es gibt zwei einfache Wege, um das Problem zu beheben. Die bequemste Variante ist, Spotify als Flatpak zu installieren. Die Flatpak-Version zeigt den blauen Rahmen nicht und ihr müsst euch um nichts kümmern. Änderungen an der Konfiguration sind nicht nötig.
Die Flatpak-Version von Spotify zeigt den blauen Rahmen nicht, die GTK-Style-Window-Decoration wird korrekt dargestellt und das Fenster sieht nach der Installation normal und fehlerfrei aus.
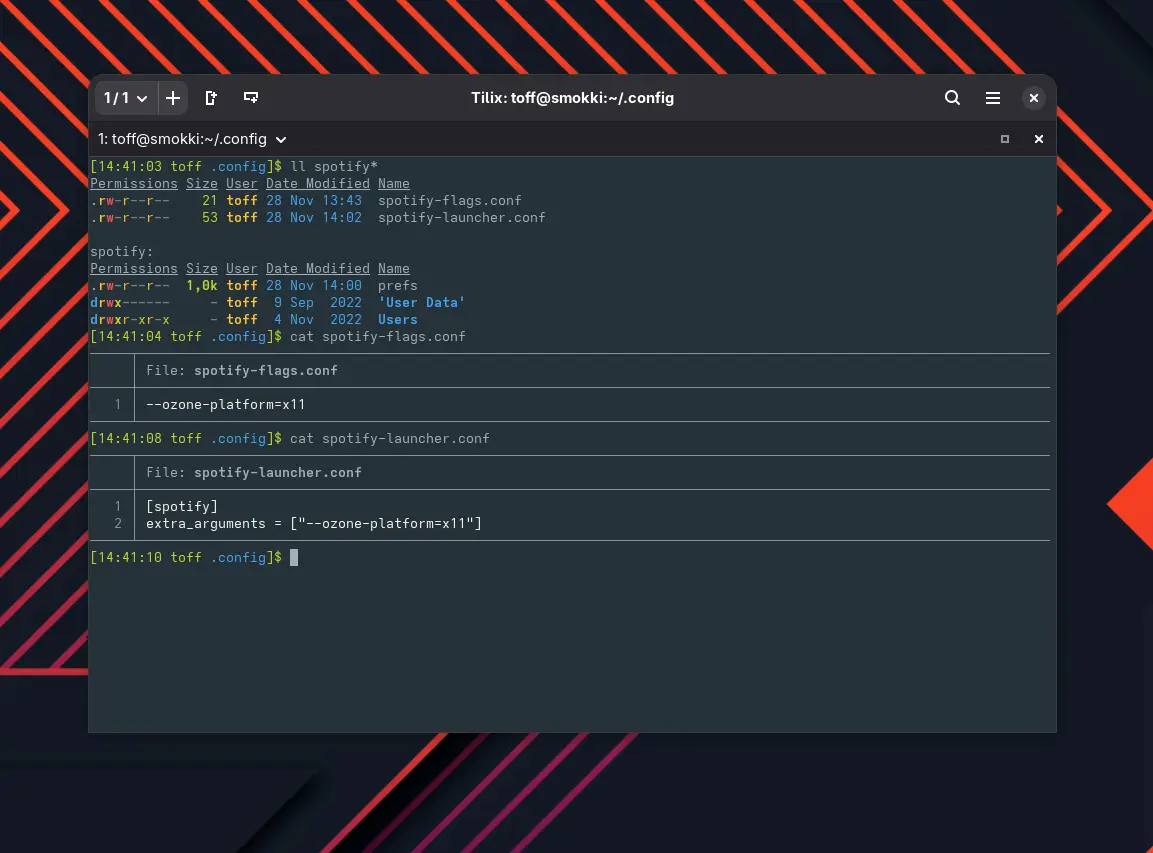
Falls ihr Spotify hingegen über den Spotify Launcher (Paket spotify-launcher aus den Extra-Quellen von Arch) oder direkt aus dem AUR (Eintrag spotify) installiert habt, müsst ihr das Start-Flag --ozone-platform=x11 setzen. Damit wird die GTK-Dekoration korrekt angezeigt. Je nach Installationsart fügt ihr das Flag wie folgt ein:
Für AUR-Spotify in der Datei ~/.config/spotify-flags.conf:
--ozone-platform=x11
Für Spotify Launcher in ~/.config/spotify-launcher.conf:
Eventuell müsst ihr diese Dateien erst anlegen. Nach einem Neustart von Spotify sollte der blaue Rahmen verschwunden sein und alles wieder normal aussehen.
Die Konfigurationen unter ~/.config. Die Dateien müssen eventuell erst erstellt werden, ihr braucht nur die passende Datei je nach Installationsart, nicht beide gleichzeitig.Alternativ könnt ihr das Flag –ozone-platform=x11 setzen, wenn ihr Spotify aus dem AUR installiert habt. Dann wird der Fensterrahmen wieder korrekt angezeigt und normal dargestellt.
Korrektur von Fabian auf Mastodon: Das stimmt so nicht. Das ist ganz alleine dem geschulded das Spotify Wayland-nativ läuft und dort, unter GNOME, eine clientseitige Dekoration (CSD) braucht, die es über diese blaue bereit stellt. Das ganze wieder zu X11 zwingen schafft eventuell echte Probleme, wie verschwommene Schriften, schlechtes (kein) scaling und so weiter. Spotify ist auch nicht Elektron, sondern Chromium Embedded Framework (CEF).
Klar, es ist eine Krücke, aber eine die derzeit hilft. Die Änderung lässt sich ja auch schnell wieder rückgängig machen. Die anderen Optionen wären, Gnome unter X11 zu betreiben oder sich mit den blauen Rahmen anzufreunden. Beides in meinen Augen auch nicht gerade optimal. So ist es erstmal ein Workaround, den man natürlich nicht vergessen sollte, falls sich Spotify irgendwann einmal wieder komisch verhält.
Wenn ich unter Linux einen Artikel schreibe oder einen Blogbeitrag vorbereite, brauche ich oft ein paar passende Screenshots. Das klingt erstmal banal: Bildschirmfoto machen, zuschneiden, fertig. Doch in der Praxis steckt oft mehr dahinter. Ich will Fenster freistellen, bestimmte Inhalte unkenntlich machen oder die Aufmerksamkeit auf einen bestimmten Bereich lenken.
Unter KDE ist das mit Spectacle und KSnip angenehm gelöst. In Kombination hat man mit den beiden Programmen zwei leistungsfähige Werkzeuge für Screenshots mit Anmerkungen, Schatten, Pfeilen, Transparenz und mehr. Unter GNOME sieht es – gerade unter Wayland – etwas magerer aus.
Früher habe ich oft Shutter verwendet. Das konnte alles, was ich gebraucht habe – bis auf Wayland. Seit der Umstellung auf das moderne Display-Server-Protokoll ist Shutter leider keine Option mehr. Die KDE-Tools funktionieren zwar mit Wayland, benötigen als Unterbau jedoch den KWin-Fenstermanager, da jeder Fenstermanager die Screenshot-Funktionen selbst implementieren muss. Hier kommt nun aber Gradia ins Spiel.
Einheitlicher Look für Screenshots
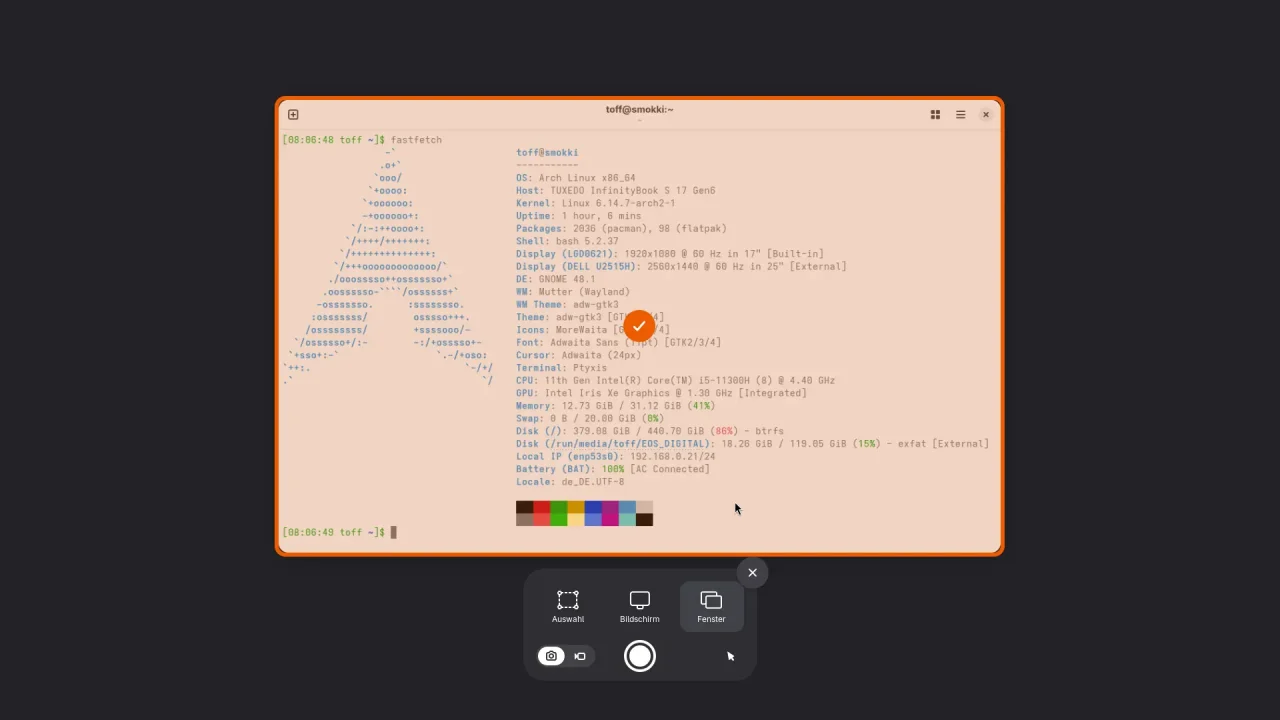
Gradia ist kein klassisches Screenshot-Werkzeug. Ihr könnt damit keine Bildschirmfotos aufnehmen – das übernimmt weiterhin das GNOME-eigene Screenshot-Tool (erreichbar per Druck-Taste, über das Anwendungsmenü oder per Shell-Erweiterung). Was Gradia bietet, ist eine unkomplizierte Nachbearbeitung: Ihr zieht ein bereits aufgenommenes Fensterbild hinein oder übernehmt es aus der Zwischenablage und Gradia poliert es optisch ein wenig auf.
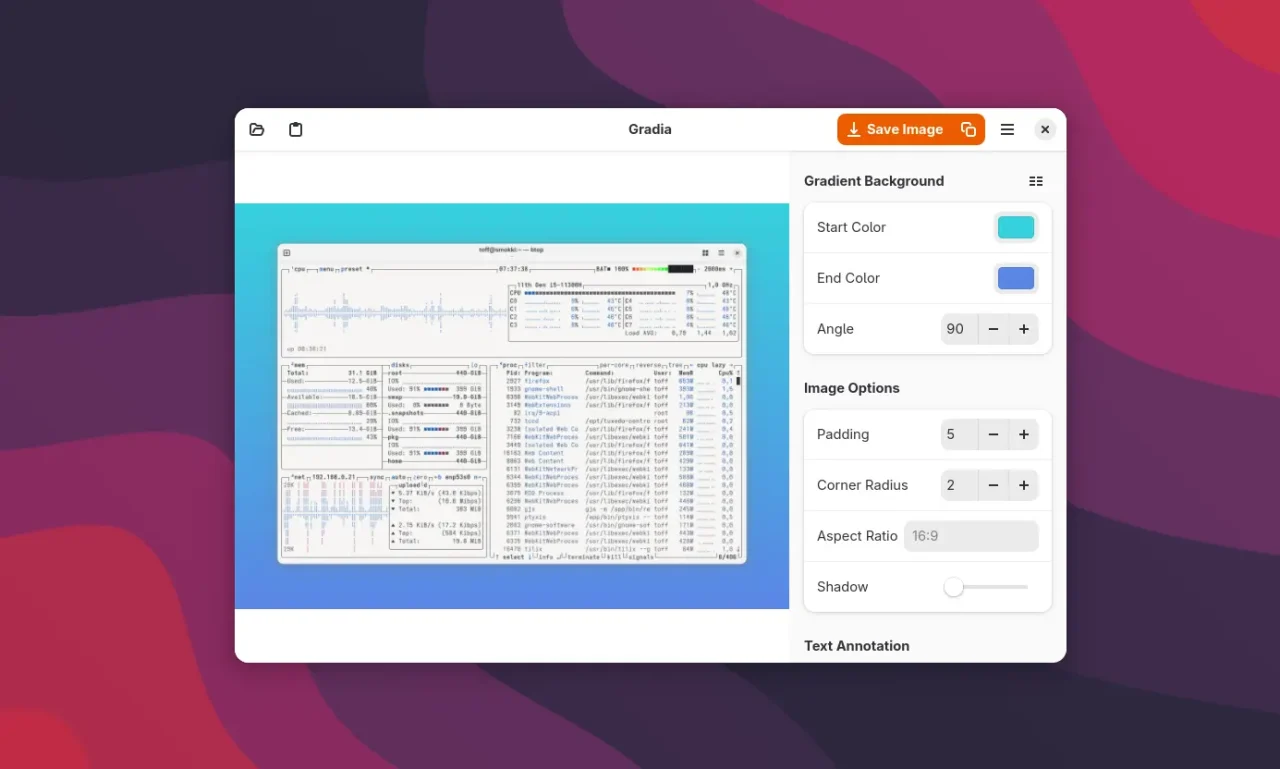
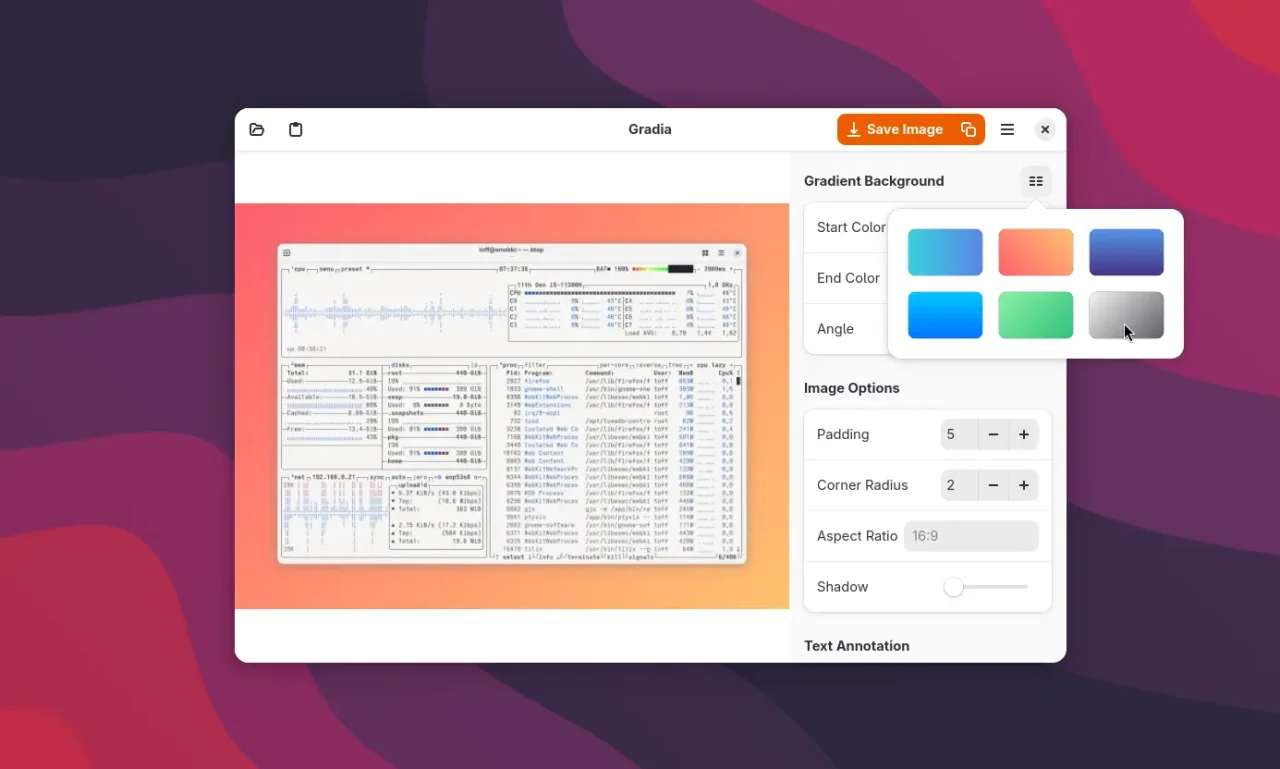
Mit der Erweiterung Screenshort-cut landen Fenster-Screenshots direkt in der Zwischenablage. Praktisch, um sie sofort in Gradia weiterzuverarbeiten, ohne den Umweg über Dateien.Ein Klick auf den Einfüge-Button genügt: Gradia übernimmt das Screenshot aus der Zwischenablage und bereitet es automatisch mit Hintergrund und Freistellung auf.Die Hintergrundfarbe oder der Verlauf lassen sich flexibel anpassen. Genau wie der Randabstand, der für ein luftigeres Layout besonders bei Social-Media-Postings sorgt.
Das funktioniert absolut simpel: Gradia erkennt automatisch den transparenten Fensterrand und legt einen Hintergrund mit Farbverlauf dahinter. Statt eines klassischen transparenten PNGs mit Schatten kommt ein Bild heraus, das sich auch auf dunklem oder hellem Hintergrund gut macht. Die abgerundeten Fensterecken lassen sich zusätzlich betonen, und ihr könnt den Abstand zum Bildrand individuell anpassen. So wirkt das Fenster im Screenshot „freigestellt“ und hebt sich besser vom Hintergrund ab.
Gradia gibt es als Flatpak und lässt sich bequem über Flathub installieren. Wer Flatpak noch nicht eingerichtet hat, findet auf Flathub selbst Anleitungen für so gut wie jede Linux-Distribution. Der unter der GPL-3.0 lizenzierte Quellcode von Gradia ist auf GitHub einsehbar. Die Versionsnummern wirken dort allerdings etwas uneinheitlich: Auf Flathub steht der Zähler bei Version 1.1.0, auf GitHub ist Version 0.2 die aktuellste, obwohl auch eine Version 0.3 existiert, die jedoch älter ist.
Kein Ersatz für Shutter – aber eine gute Ergänzung
Gradia ist klein, schnell installiert und macht genau eine Sache, die aber ordentlich. Wer unter GNOME arbeitet und ästhetische Screenshots für Veröffentlichungen im Netz oder auf Social Media braucht, bekommt mit Gradia ein praktisches Helferlein. Ich hoffe, dass das Tool noch etwas weiterentwickelt wird. Ein simples Annotationswerkzeug oder das Unkenntlichmachen von Bildbereichen wären zum Beispiel sinnvolle Ergänzungen. Aber auch so ist es ein nützliches Werkzeug im GNOME-Kosmos.
Ich bin gerade in der Situation, dass ich meinen Arbeitsplatz ein wenig umgestalten möchte. Die Monitoren sollen nicht mehr nur einfach auf dem Schreibtisch stehen, sondern auf einem Gestell an den Tisch geklemmt werden — Ergo: mehr Platz auf dem Tisch. Nun gilt es dabei ein paar Dinge zu beachten. Etwa die Frage, wie schwer meine Monitore eigentlich sind. Da ich keine Lust habe alles abzubauen und die Geräte auf die Waage zu stellen, wäre es recht nett zu wissen, vor was für Geräten ich da eigentlich täglich sitze. Da Information könnte ich sicherlich aus alten Rechnungen herauskramen, doch das geht sicherlich auch ein wenig cleverer.
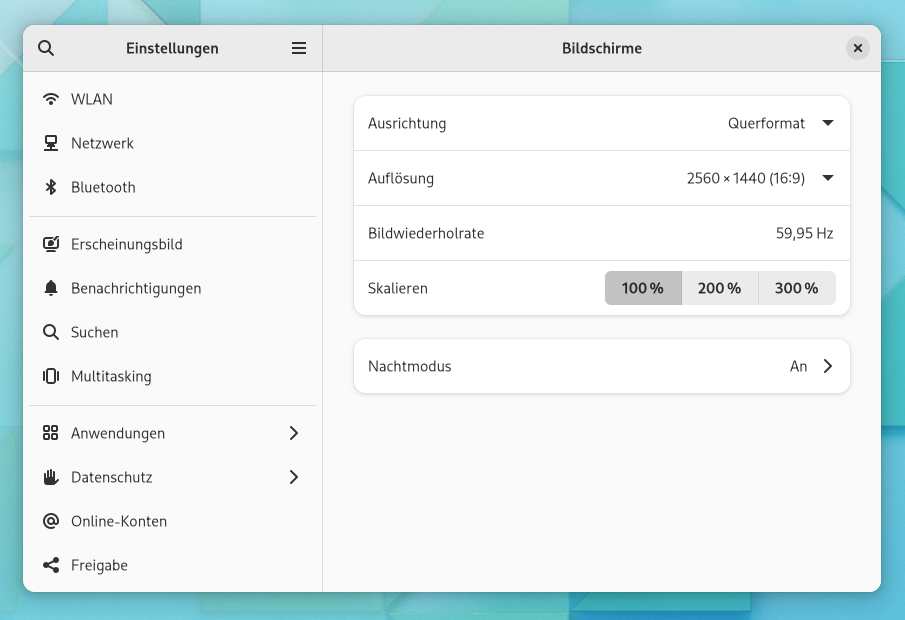
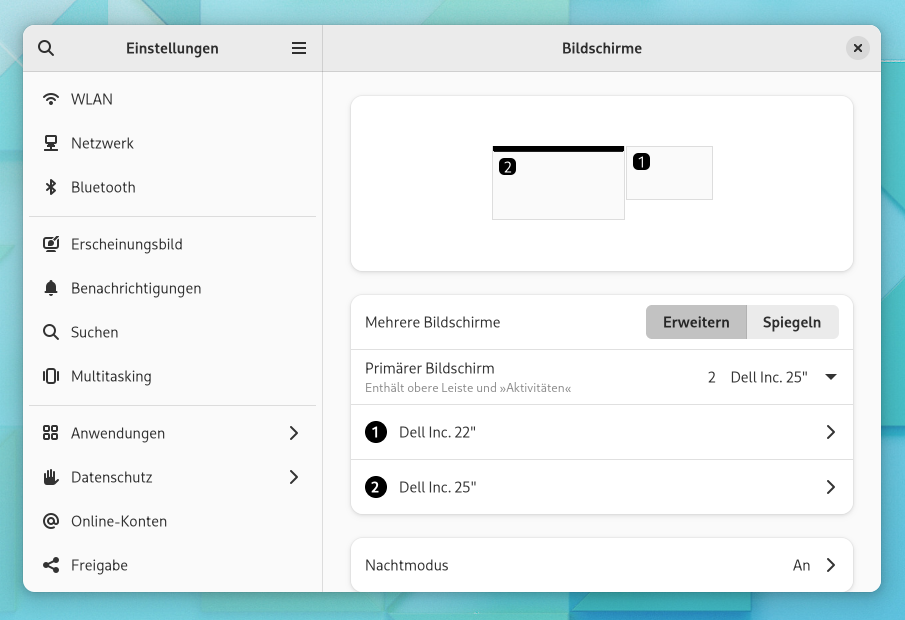
Das Logo des Herstellers glitzert mir auf der Frontseite des Gehäuses entgegen, doch weitere Informationen zum Gerät finden sich dort nicht. Und auch auf der Rückseite gibt es keine weiteren Details. Ein Schildchen mit der Typenbezeichnung gab es in der Regel bei den guten alten Röhrenmonitoren, doch bei meinen aktuellen Dell-Flatscreens findet sich dort nichts mehr. Auch die Monitor-Einstellungen der Gnome-Desktopumgebung lässt den Nutzer im Stich. Die zeigen nur dann Informationen zum Typ des Monitors an, wenn zwei Displays angeschlossen sind. Mehr als den Hersteller und die Bildschirmdiagonale erfährt man jedoch nicht.
Gnome geizt mit Informationen
Hat man nur einen Monitor am Rechner angeschlossen, zeigt Gnome rein gar nichts zum Display an.Bei zwei angeschlossenen Geräten erhält man wenigstens Informationen zum Hersteller und zur Größe.
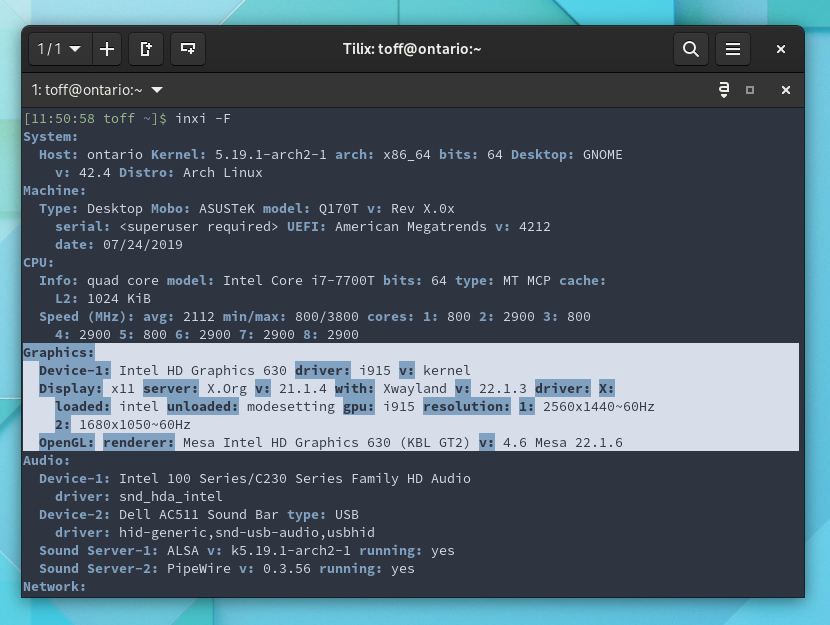
Wenn die grafischen Tools so sparsam mit Informationen sind, dann hilft doch sicherlich das Terminal. Tools zur Anzeige von Hardware-Informationen gibt es unter Linux ja wie Sand am Meer, da müsste doch was dabei sein. Das Go-To-Werkzeug für diese Aufgabe wäre hier Inxi, das sich bei vielen Distributionen aus den Paketquellen installieren lässt (etwa via pacman -S inxi bei Arch Linux oder apt install inxi bei Ubuntu, Debian und Derivaten). Das Kommando inxi -F spuckt dann sämtliche Details zum System aus, aber auch hier Pustekuchen: keine Details zu den angeschlossenen Monitoren.
Auch das Hardware-Analyse-Tool Inxi gibt keine Details zu den Monitoren aus.
Details zum Monitor über das Terminal
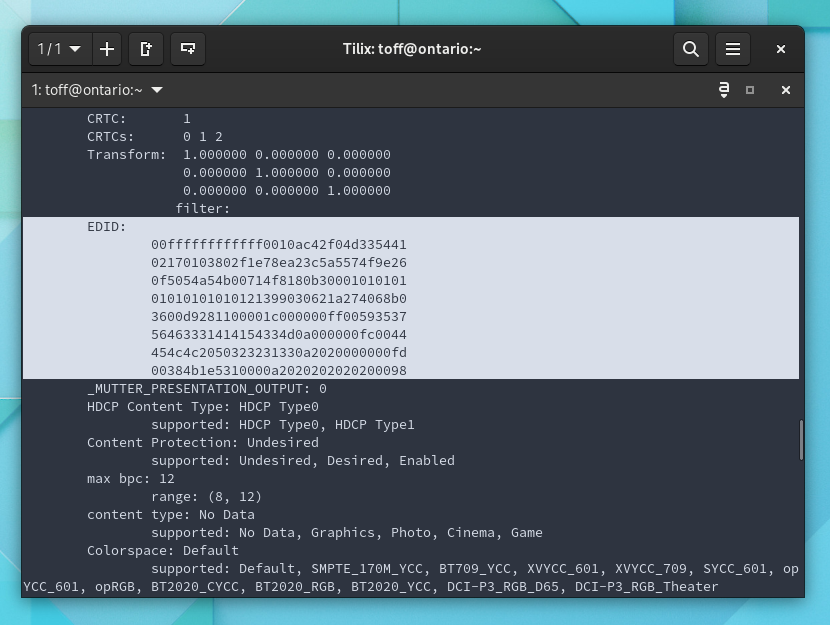
Um mir eine weitere Suche unter den zahlreichen Tools zu ersparen, greife ich nun gleich auf das „richtige“ Werkzeug zurück. Details zum Displayserver liefert das Kommandozeilenwerkzeug Xrandr. Tools wie Inxi machen in der Regel nichts anderes, also solche Kommandos auszuführen und die Ausgabe optisch aufgewertet anzuzeigen. Über xrandr -q --verbose bekommt man also zahlreiche Details zu den unterstützten Auflösungen und Wiederholraten, doch der Name und Typ des Monitors fehlt immer noch. Aber nicht ganz: Die Daten sind im Feld EDID oder Extended Display Identification Data codiert.
Xrandr liefert endlich Details, diese sind allerdings kryptisch verschlüsselt.
Wer diese Daten nun jetzt nicht von Hand decodieren möchte, muss sich ein wenig unter die Arme greifen lassen. Das bei Stack Overflow gepostete Skript beispielsweise braucht keine weiteren Helferlein, um die EDID zu dekodieren. Ihr speichert folgenden Code einfach als monitor.sh ab und macht die Skriptdatei via chmod +x monitor.sh ausführbar. Aus dem Terminal heraus aufgerufen, zeigt das Skript dann die angeschlossenen Monitore inklusive den Namen des Herstellers und der Typenbezeichnung an. Technische Details zu Auflösungen oder Wiederholraten fehlen, doch die lassen sich ja auch an zahlreichen anderen Stellen ermitteln.
Alternativ holt ihr euch das Paket edid-decode auf den Rechner. Bei Ubuntu/Debian oder Linux Mint direkt über die offiziellen Paketquellen (via apt install edid-decode), bei Arch Linux oder Manjaro lediglich über das AUR (etwa mit einem AUR-Helper via yay -S edid-decode-git). Hier genügt dann der folgende Einzeiler, der allerdings nicht mit dem proprietären Nvidia-Treiber funktioniert. Hier bekommt ihr dann allerdings nicht nur den Hersteller und den Monitortyp angezeigt, sondern auch gleich die Seriennummer der Geräte — falls ihr an diesen Interesse haben solltet.
$ for file in $(ls -1 /sys/class/drm/*/edid); do text=$(tr -d 0 <"$file"); if [ -n "$text" ]; then edid-decode "$file" | grep -e Manufacturer: -e Product; sleep 0.0001; fi done
Vendor & Product Identification:
Manufacturer: DEL
Display Product Serial Number: '9X2VY55I0J0L'
Display Product Name: 'DELL U2515H'
Vendor & Product Identification:
Manufacturer: DEL
Display Product Serial Number: 'Y57VF31AAT3M'
Display Product Name: 'DELL P2213'
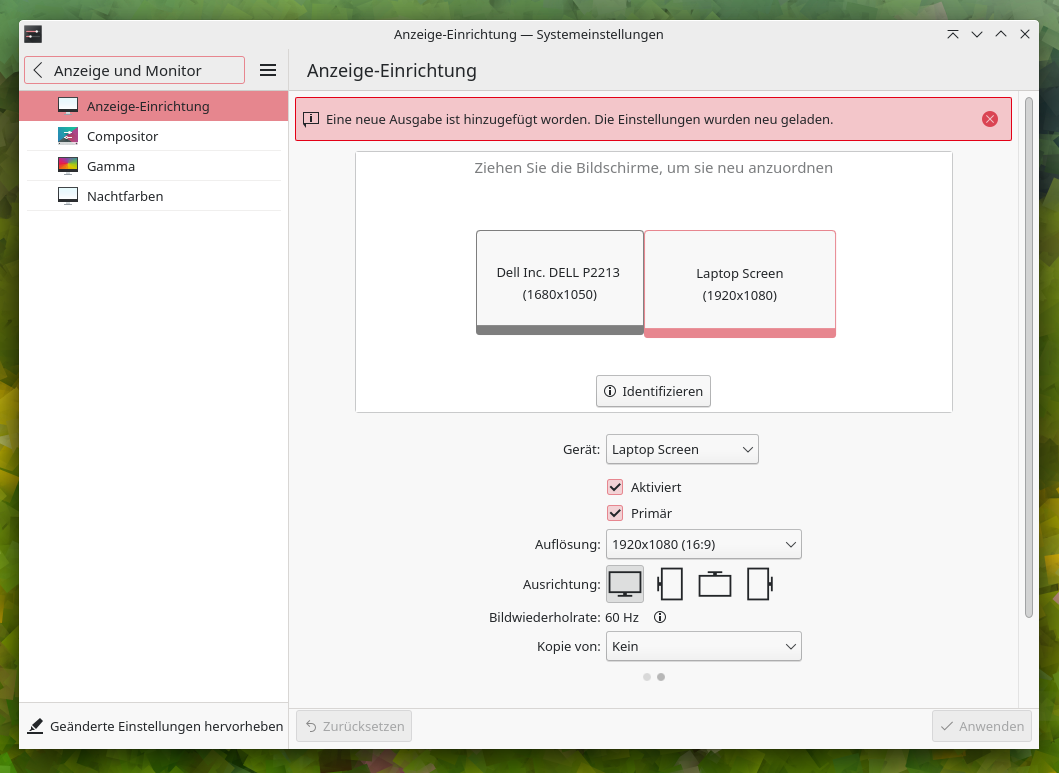
Letztendlich wäre es natürlich schneller gewesen die alten Rechnungen herauszusuchen, oder vielleicht auch mal einen Blick über den Tellerrand zu KDE zu werfen. Im Gegensatz zu den Einstellungen von Gnome zeigen die Systemeinstellungen von KDE nämlich gleich die Bildschirmkennungen mit an. Wie immer ist Gnome ein wenig arg spartanisch und geizig mit Funktionen und Details. In meinen Augen dürften die System-Settings von Gnome ruhig auch die Bezeichnungen ausgeben. Nötig sind sie in der Regel nicht, doch ab und an können sie doch auch praktisch sein.
Die Anzeige-Einrichtung von KDE zeigt die Typenbezeichnung des Monitors im Gegensatz zu Gnome an.
Erweiterungen für den Gnome-Desktop sind eine zweischneidige Sache: Auf der einen Seite lässt sich auf diesem Weg so gut wie jedes Detail des Desktops anpassen, auf der anderen Seite gab es in der Vergangenheit bei Upgrades auf die jeweils nächste Gnome-Version immer wieder Probleme. Ich hatte schon das Vergnügen, dass ich in der virtuellen Konsole die Konfigurationsdateien von Gnome löschen musste, um mich wieder ins System einloggen zu können — ohne diese Aktion lud Gnome nur den blanken Hintergrund. Da ich nun aber schon seit einiger Zeit auf Experimente mit Erweiterungen verzichte, kann nicht ich sagen, ob sich die Situation inzwischen grundlegend verbessert hat. Ich lese in Foren und Blogs allerdings weitaus seltener negative Berichte. Nicht desto trotz empfehle ich vor dem Einspielen „großer“ Gnome-Updates die gerade aktivierten Erweiterungen vorübergehend zu deaktivieren.
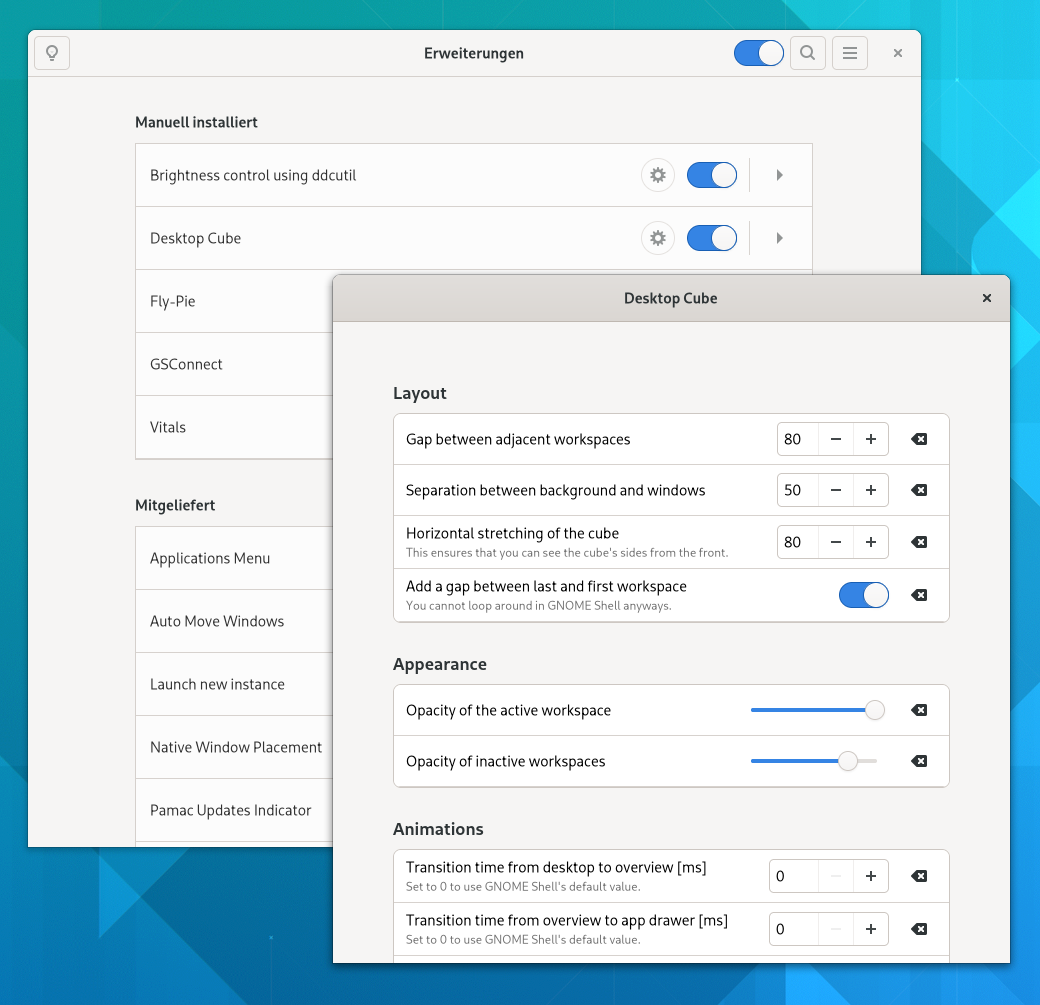
Es gibt aber durchaus ein paar Erweiterungen, die ich nicht missen möchte: Dazu gehört zum Beispiel GSConnect zum Andocken des Desktops an KDE Connect, sodass Benachrichtigungen des Handys an den Desktop weitergeleitet werden oder die Musikwiedergabe automatisch stoppt, sobald ein Anruf eingeht. Der Abgleich der Zwischenablage für Copy&Paste ist auch praktisch. Aus Nostalgiegründen gehört aber aktuell auch der Desktop Cube dazu. Die Erweiterung ergänzt Gnome mit einem 3D-Würfel, wie ihr ihn eventuell noch von Compiz her kennt — einen Rechner mit schneller Grafikkarte braucht es dafür nicht zwingend. Bei mir genügt ein Intel Core i7-7700T mit einer internen HD Graphics 630. An der Erweiterung wird auf Github aktuell aktiv gearbeitet, die fünfte Version des Addons wurde gerade erst vor zwei Tagen veröffentlicht. Neu ist ein einfacher Dialog zur Konfiguration der wichtigsten Parameter, sodass ihr den Würfel an eure eigenen Vorstellungen anpassen könnt.
Bei einer Rolling-Release-Distribution wie Arch Linux oder Manjaro spült es nicht nur immer wieder neue Programm- oder Kernel-Versionen in das System, sondern auch wichtige Bibliotheken und Systemkomponenten in deren neusten Ausgaben. So wie heute: Wer gerade das Pacman-Upgrade anwirft, dem installiert der Paketmanager zahlreiche Python-Pakete in der Version 3.10, die Anfang Oktober veröffentlicht wurde. Für Arch-Nutzer gibt es dabei im Endeffekt nicht viel zu beachten, vom Upgrade betroffene Pakete werden automatisch aktualisiert, habt ihr allerdings AUR-Pakete auf dem System, dann müsst ihr diese eventuell neu bauen.
Welche Pakete auf eurem System betroffen sind, ermittelt ihr über das Kommando pacman -Qoq /usr/lib/python3.9. Sollte das System hier ein oder mehrere Namen ausspucken, dann müsst ihr diese über euren AUR-Helper neu erstellen, um in Zukunft Fehler beim Ausführen der entsprechenden Anwendungen auszuschließen. Die schnellste und einfachste Methode dafür ist, die Liste an euren AUR-Helper zu übergeben. Beachtet dazu das zweite Kommando aus dem folgenden Listing. Tauscht den Aufruf des AUR-Helpers, hier paru, gegen das von euch genutzte Programm aus. Zur Kontrolle prüft ihr am Ende, ob es nun keine veralteten Programme mehr gibt.
Die Aktion ist bei allen Systemen nötig, die auf Arch Linux aufsetzen und das AUR integrieren. Dazu gehören natürlich Arch Linux selbst sowie äußerst beliebte Derivate wie Manjaro, aber auch eher Exoten wie ArcoLinux, Chakra oder KaOS. Eine Liste der zahlreichen Arch-Linux-Derivate pflegt das Arch Wiki. Auch wird es nicht das letzte Mal sein, dass die Python-Anwendungen aus dem AUR neu gebaut werden müssen, da nächste Python-Update kommt bestimmt.
Das Open-Source-Universum rund um freie Software ist schier unüberschaubar geworden. Seit Jahrzehnten angewachsen, gibt es Programme für so gut wie jeden Zweck. Unter Linux lassen sich viele dieser Anwendungen über die Paketverwaltung komfortabel installieren und aktuell halten, doch keine Distribution integriert jede Software in ihre Repositories. Schon alleine die offiziellen Paketquellen unterscheiden zwischen Paketen, die direkt von den Entwicklern der Distribution betreut werden (Arch: Core und Extra, Ubuntu: Main) und Paketen, die von der Community gepflegt werden (Arch: Community, Ubuntu: Universe). In der Praxis macht das für den Nutzer der Distribution in der Regel jedoch kaum einen Unterschied.
Sehr neue Entwicklungen und gerade frisch gestartete Software-Ideen müssen hingegen entweder von Hand oder über aus von den Projekten betrieben Paketquellen integriert werden — wenn es denn überhaupt welche gibt. Nur Arch Linux geht hier wieder einen komplett eigenen Weg, das Arch User Repository oder kurz AUR vereinfacht die Installation fremder Software ganz wesentlich. Wer Arch Linux oder eines seiner Derivate wie etwa Manjaro noch nicht kennt, dem sagt das AUR vielleicht noch nichts: Im Vergleich zu herkömmlichen Paketquellen pflegt das AUR keine Binärpakete, sondern lediglich eine Sammlung von Kochrezepten, die dem System per Skript erklären, wie sich eine Software optimal in das Arch-System integrieren lässt.
Das Arch User Repository
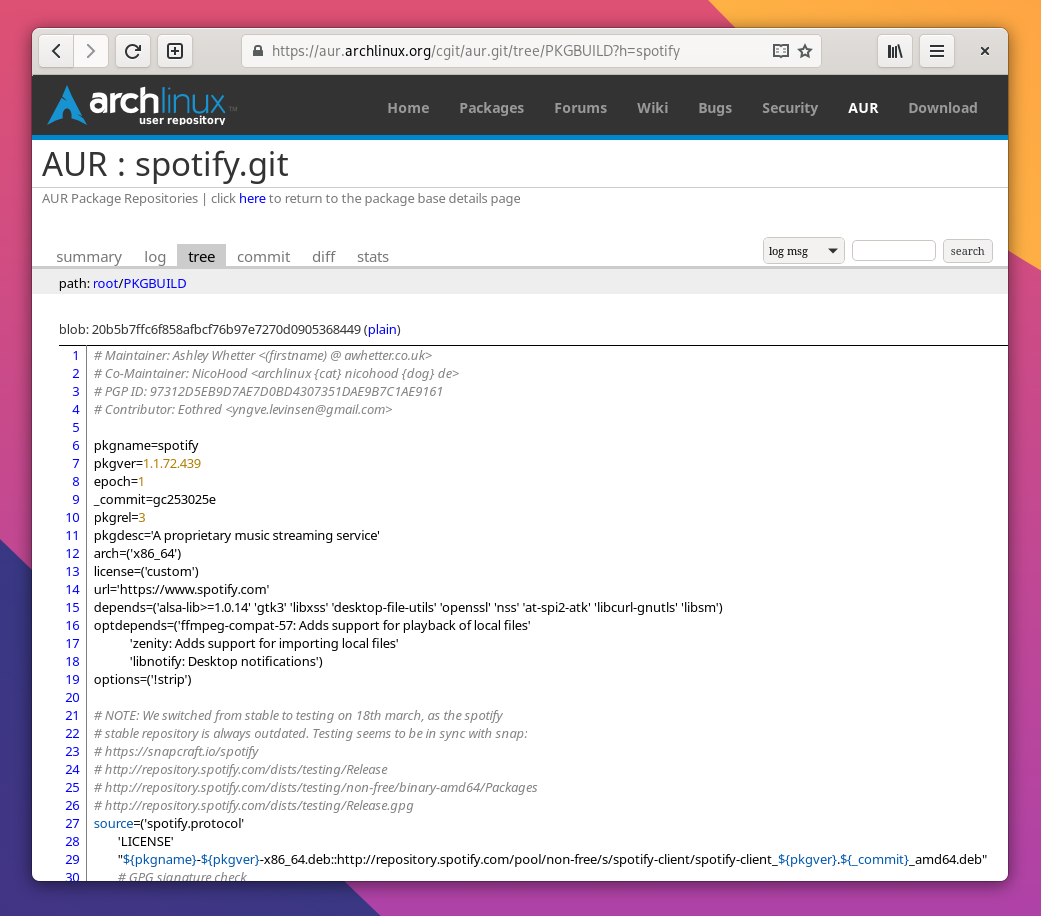
Die dafür notwendige PKGBUILD-Datei (hier am Beispiel von Spotify) enthält Informationen, woher die Anwendung herunterzuladen und wie sie zu installieren ist, inklusive einer Reihe von Anpassungen, plus die benötigten Abhängigkeiten aus der Paketverwaltung. So lässt sich so gut wie jedes Programm ohne große Komplikationen installieren, egal ob es die Entwickler nur in Form des Quellcodes, über DEB- oder RPM-Pakete oder statisch gebaute Binaries bereitstellen. Unter Arch lassen sich so sehr einfach proprietäre Anwendungen wie Chrome oder Spotify installieren oder eben auch ganz neue Entwicklungen. Es braucht nur eine Person, die sich mit dem Schreiben einer PKGBUILD-Datei auskennt — und davon gibt es in der Arch-Linux-Community so einige.
Das Arch User Repository enthält selbst keine Software, sondern lediglich Kochrezepte zum Bauen von Paketen in Form von PKGBUILD-Dateien wie hier am Beispiel von Spotify.
Allerdings braucht es wie immer bei Fremdpaketen einen Disclaimer: Die Hürden Änderungen in das AUR einzubringen oder gar AUR-Pakete zu betreuen, sind im Vergleich zu denen in der Karriere eines offiziellen Arch-Entwicklers geringer. Von daher ist es durchaus möglich, dass Menschen mit schlechten Absichten Manipulationen oder gar Malware in das AUR einbringen. 2018 ist das bereits passiert, damals gab es einen Angriff auf den AUR-Eintrag des Acrobat Readers und zweier weiterer PKGBUILDs. Das AUR ist allerdings auch kein wilder Spielplatz für Bastler und Hacker, eine Gruppe von Trusted Users überwacht das Geschehen im AUR, korrigiert Fehler und leitet neue Beitragende an. In der Praxis lässt sich das AUR daher gut nutzen, zur Sicherheit sollte man allerdings immer mal in die PKGBUILD-Dateien sehen und kontrollieren, ob die Software zum Beispiel von den offiziellen Seiten des entsprechenden Projekts geladen wird.
AUR-Helper helfen im Alltag
Nun zurück zum Thema: Das AUR ist wie angesprochen kein Selbstläufer. Es enthält selbst keine Software oder fertige Pakete, sondern lediglich Skripte zum Bauen von Arch-Paketen. Der offizielle Installationsweg führt somit über das Auschecken der PKGBUILD-Datei aus dem Github-Repository des AUR, danach kontrolliert ihr die PKGBUILD und baut im letzten Schritt letztlich mit makepkg -si das Paket. Der Schalter -i am Ende installiert das am Ende erstellte Paket, dabei werden automatisch die im PKGBUILD definierten Abhängigkeiten aus der Paketverwaltung nachgezogen. Alle während dieses Prozesses heruntergeladenen und gebauten Daten braucht ihr am Ende nicht mehr, daher führte ich diese Schritte gerne im Ordner /tmp des Systems aus. Es sei denn, ich möchte die Daten auf anderen System wiederverwenden.
$ pacman -S --needed base-devel git
$ git clone https://aur.archlinux.org/spotify.git
$ cd spotify
$ less PKGBUILD ### Mit [Q] beenden
$ makepkg -si
Es gibt viele Arch Nutzer, die generell diesen Weg gehen, so behalten sie die volle Kontrolle über den Vorgang. Allerdings gibt es spätestens dann beim Bauen der AUR-Pakete Probleme, wenn diese selbst zusätzliche Pakete aus dem AUR benötigen. Benötigen diese zusätzlichen Pakete wieder andere Pakete aus dem AUR, wird es arg kompliziert. Aus diesem Grund gibt es eine Reihe von Programmen, AUR-Helper genannt, die den Nutzer bei der Installation von AUR-Paketen unterstützen. Sie automatisieren die oben genannten Schritte und lösen Abhängigkeiten automatisch auf, sodass sich die Installation von Paketen aus dem AUR oft nicht anders anfühlt, als die Installation von Software aus den offiziellen Paketquellen. In der Regel übernehmen die AUR-Helper sogar die Syntax des Arch-Linux-Paketmanagers Pacman.
### AUR-Helper wie Yay oder Pacaur erleichtern die Arbeit
### mit Software aus dem Arch User Repository:
$ yay -S spotify
$ pacaur -S spotify
$ paru -S spotify
### Beim Update kann man sich das 'pacman -Syu' sparen.
### Die AUR-Helper übernehmen die Syntax von Pacman und
### rufen neben den eigen Update auch die aus der Paket-
### verwaltung ab.
$ yay -Syu
$ pacaur -Syu
$ paru -Syu
In der Geschichte der AUR-Helper gibt es immer mal wieder ein hin und her. Bis vor ein paar Jahren war Yaourt (Yet another AUR Helper) das Maß aller Dinge: Das Programm war das einzige, das AUR-Abhängigkeiten automatisch auflöste und vor allen Dingen alle Interaktionen mit dem Nutzer vor dem Build-Vorgang klärte, sodass das eigentliche Bauen später ohne Unterbrechungen in einem Rutsch erfolgte. Eine große Erleichterung, da das Bauen manche Pakete durchaus längere Zeit in Anspruch nimmt, besonders wenn diese aus dem Quellcode kompiliert werden. Doch mit der Version 1.9 stellte der Yaourt-Entwickler seine Arbeit ein, wodurch Pacaur zum Liebling der Nutzer wurde. Bis auch hier wieder der Entwickler goodbye sagte und Yay der Quasi-Standard wurde, auch wenn Pacaur inzwischen einen neuen Betreuer gefunden hat. Aktuell liegt Paru in der Gunst der User am höchsten und liegt im AUR-Ranking ganz vorne.
Ein Mix an AUR-Helfern hilft
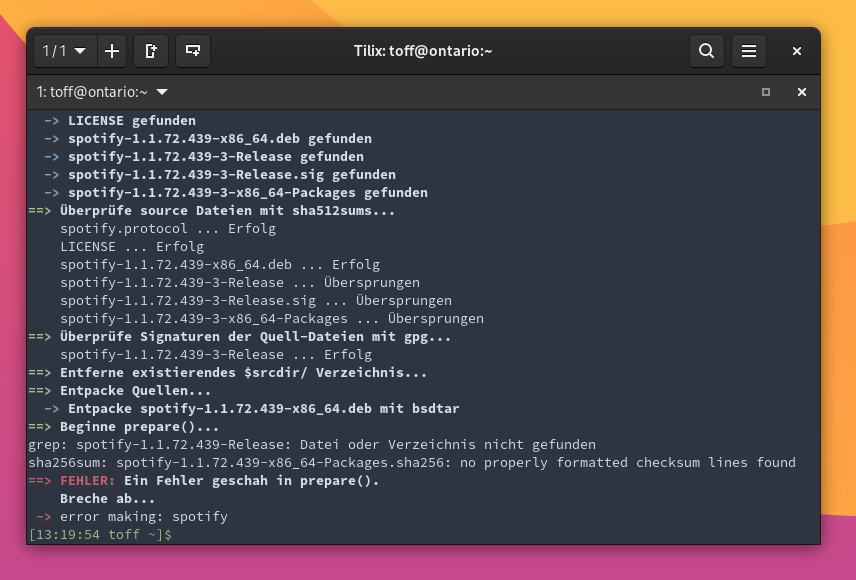
Was ist allerdings immer wieder merke: Kein AUR-Helper ist perfekt. Yay erhält zum Beispiel regelmäßig Updates (zuletzt erschien das Update auf Yay 11.0.2 Mitte Oktober 2021), doch ich stelle immer wieder fest, dass das Programm in bestimmten Situationen scheitert. Aktuell bricht Yay zum Beispiel das Bauen von Spotify ab, da Prüfsummen nicht stimmen würden. Von Hand oder mit Pacaur lässt sich das Spotify-Paket jedoch ohne Probleme erstellen. Zudem wird Yay in Go entwickelt, das auf der Festplatte bald 500 MByte belegt (Tipp: Yay über das Binary yay-bin installieren). Auf einem schlanken System würde ich daher eher zu Paru oder Pacaur greifen. Letzteres hat aber auch wieder den Nachteil, dass die Entwicklung trotz eines neuen Projektbetreuers eher still steht. Die letzte Version ist vor über zwei Jahren freigegeben worden.
$ yay -S spotify
[...]
grep: spotify-1.1.72.439-Release: No such file or directory
sha256sum: spotify-1.1.72.439-x86_64-Packages.sha256: no properly formatted checksum lines found
==> ERROR: A failure occurred in prepare().
Aborting...
-> error making: spotify
Es passiert auf meinem System nicht das erste Mal, dass Yay einen Fehler beim Bauen eines AUR-Pakets auswirft und den Vorgang ohne Erfolg abbricht.
Ideal ist es daher in meinen Augen einen Mix an AUR-Helpern auf einem Arch-System bereitzuhalten und bei Fehlern im Build-Prozess erst einmal einen anderen AUR-Helfer zu testen, bevor man sich auf die Fehlersuche begibt oder gar einen Kommentar unter dem AUR-Eintrag im Repository hinterlässt. Bei mir hat schon mehrmals Yay einen Fehler ausgespuckt, während Pacaur ohne Problem das PKGBUILD abarbeitete und anders herum. Ich persönlich empfehle schon alleine aufgrund des schlankeren Unterbaus generell Paru und Pacaur, wobei Paru euer Hauptprogramm sein sollte — nicht ohne Grund ist Paru das am häufigsten installierte Paket aus dem AUR. Pacaur spielt bei mir die zweite Geige, ist aber immer ein gutes Backup. Yay versuche ich inzwischen zu vermeiden, auch wenn das Kommando yay -Syu bei mir im Gedächtnis eingebrannt ist.
### Installation von Paru
$ sudo pacman -S --needed base-devel
$ git clone https://aur.archlinux.org/paru.git
$ cd paru
$ makepkg -si
### Installation von Yay:
$ pacman -S --needed base-devel git
$ git clone https://aur.archlinux.org/yay.git
$ cd yay
$ makepkg -si
### Alternativ Yay als Binary:
$ git clone https://aur.archlinux.org/yay-bin.git
$ cd yay-bin
$ makepkg -si
### Installation von Pacaur:
$ pacman -S --needed base-devel git
$ git clone https://aur.archlinux.org/pacaur.git
$ cd pacaur
$ makepkg -si
Über die Jahre haben sich bei mir hier unzählige USB-Sticks und SD-Speicherkarten angesammelt. Oft stammen diese nicht von Markenherstellern, sondern aus der Ramschkiste von Werbematerialprovidern — Pressekonferenzen und Produktpräsentationen sei Dank. In der Praxis merke ich jedoch, dass es durchaus einen Unterschied macht, ob ein Speicherstick von Sandisk, Samsung und einem anderen renommierten Hersteller stammt oder ob das Werbematerial aus irgendeiner asiatischen Hinterhofbude zusammengeschustert wurde. Und dabei rede ich nicht einmal von Fälschungen, die mehr Kapazität vortäuschen, sondern einfach nur von schlechter Qualität und Schreib-/Lesefehlern.
Ich hatte in der letzten Zeit häufig das Problem, dass sich diese miesen Sticks immer oben im Stapel ansammelten und somit beim Griff in die Grabbelkiste immer als erste in meiner Hand lagen. Spätestens beim Schreiben größerer Datenmengen, etwa eines ISO-Images einer Linux-Distribution, kommt es dann zu Problemen. Die Schreib-/Leserate bricht ein oder es gibt gleich aussagekräftigere IO-Fehler. Um diese Problematik auszuschließen, möchte ich also alle meine USB-Sticks und SD-Speicherkarten einmal auf Fehler überprüfen und defekte Datenträger für immer aussortieren. Unter Linux geht das mit Bordmitteln.
USB-Sticks auf Fehler prüfen
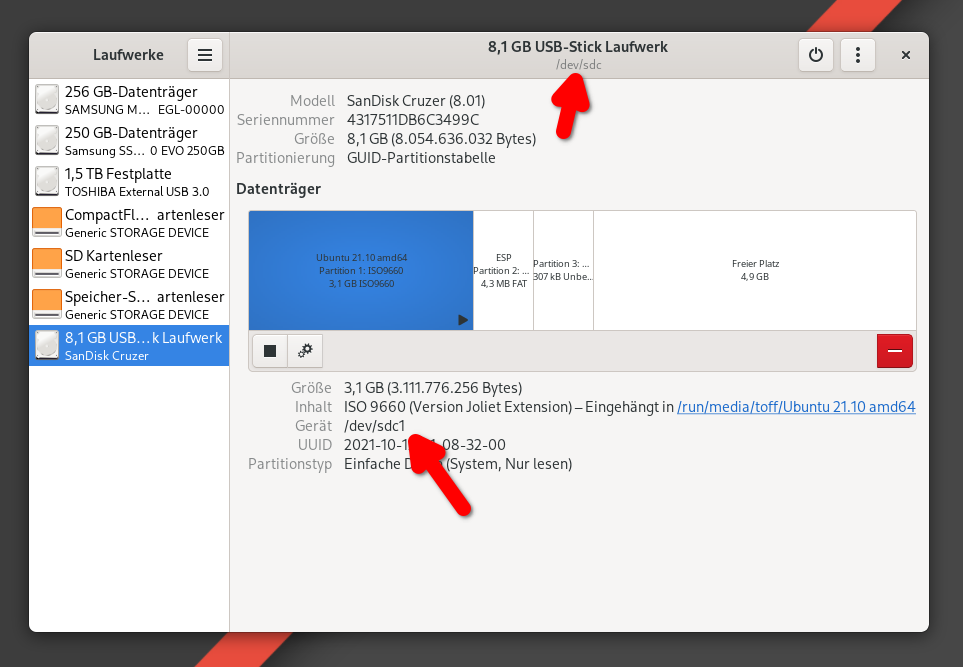
Im ersten Schritt müsst ihr die Geräte-ID des USB-Sticks oder der Speicherkarte herausfinden. Steckt den Datenträger daher an den Rechner an oder legt die SD-Karte in das entsprechende Lesegerät und gebt im Terminal lsblk ein. Das Kommando listet euch sämtliche am Rechner angeschlossene Datenträger auf. Anhand der Größe des Datenträgers lässt sich in der Regel die Geräte-ID erkennen. In meinem Beispiel bindet das System meinen 8 GByte großen USB-Stick unter sdc (also /dev/sdc in der vollständigen Syntax) ein. Seid ihr euch nicht sicher, dann zieht den zu kontrollierenden Datenträger ab und wiederholt lsblk. Fehlt sdc in der ausgegebenen Liste, dann habt ihr die richtige Kennung. Alternativ lässt sich die Kennung auch mit grafischen Tools wie der Laufwerksverwaltung von Gnome ermitteln.
$ lsblk
[...]
sdc 8:32 1 7,5G 0 disk
├─sdc1 8:33 1 2,9G 0 part /run/media/toff/Ubuntu 21.10 amd64
├─sdc2 8:34 1 4,1M 0 part
└─sdc3 8:35 1 300K 0 part
[...]
Auch die in Gnome integrierte Laufwerksverwaltung zeigt die Geräte-IDs von Festplatten, SSDs, USB-Sticks und anderen in das System eingebundenen Datenträgern an.
Für die eigentliche Fehlersuche kommt nun das Kommando badblocks aus dem Paket e2fsprogs zum Einsatz, das zur Grundausstattung der üblichen Distributionen gehört. Es kann vorkommen, dass sich Badblocks erst einmal weigert, die Überprüfung zu starten, da das Laufwerk bereits vom System benutzt sei. In der Regel kommt das davon, dass das Betriebssystem den Datenträger automatisch einbindet, sobald ihr den USB-Stick ansteckt. Auf meinem System genügt das Antippen des Icons zum Aushängen des Laufwerks im Dateimanager nicht, ich muss die Geräte-ID des Laufwerks und der dazugehörigen Partitionen gezielt mit umount aushängen.
$ sudo badblocks -wsv /dev/sdc
/dev/sdc wird offensichtlich vom System genutzt; es ist zu unsicher, Badblocks zu starten!
$ sudo umount /dev/sdc*
umount: /dev/sdc: nicht eingehängt.
umount: /dev/sdc2: nicht eingehängt.
umount: /dev/sdc3: nicht eingehängt.
An dieser Stelle muss ich eine Warnung schreiben: Beim Prüfen auf Fehler überschreibt Badblocks sämtliche Daten und Partitionen auf dem angegebenen Datenträger. Stellt daher auf jeden Fall sicher, dass ihr die richtige Geräte-ID an das Kommando übergibt und sichert vor der Aktion wichtige Daten vom betroffenen USB-Stick oder der SD-Speicherkarte. Im Fall der Fälle könnt die Daten nach der Fehlerüberprüfung nicht wiederherstellen.
Beim Aufruf von Badblocks übergebt ihr dem Kommando die Parameter -wsv sowie die Geräte-ID. Die Parameter weisen das Programm an, einen destruktiven Schreibtest auszuführen (-w), den Fortschritt anzuzeigen (-s) und generell mehr Informationen auszugeben (-v). Der ausführliche Test beschreibt jeden Block des Datenträgers viermal hintereinander mit unterschiedlichen Mustern (0xaa, 0x55, 0xff und 0x00). Je nach Geschwindigkeit und Kapazität müsst ihr dafür eine längere Zeit einplanen. Die Prüfung des von mir im Beispiel benutzten USB-Sticks nach dem USB-2.0-Standard und 8 GByte Kapazität benötigte über eine Stunde.
$ sudo badblocks -wsv /dev/sdc
Es wird getestet Mit Muster 0xaa: 0.00% erledigt, 0:00 verstrichen. (0/0/0 Fehler) erledigt
Lesen und Vergleichen:erledigt
Es wird getestet Mit Muster 0x55: 0.00% erledigt, 23:47 verstrichen. (0/0/0 Fehler) erledigt
Lesen und Vergleichen:erledigt
Es wird getestet Mit Muster 0xff: 0.00% erledigt, 47:33 verstrichen. (0/0/0 Fehler) erledigt
Lesen und Vergleichen:erledigt
Es wird getestet Mit Muster 0x00: 0.00% erledigt, 1:11:26 verstrichen. (0/0/0 Fehler) erledigt
Lesen und Vergleichen:erledigt
Neben der destruktiven Prüfmethode unterstützt Badblocks einen zerstörungsfreien Lesen+Schreiben-Modus. Diesen aktiviert ihr mit dem Parameter -n anstatt von -w. In dieser Variante sichert Badblocks die Daten des geprüften Speicherblocks zuerst in den Arbeitsspeicher, überschreibt dann den Datenblock mit Zufallsdaten und prüft, ob die Daten korrekt geschrieben werden konnten. Abschließend schreibt Badblocks die Sicherung wieder auf den Datenträger zurück. Auf den ersten Blick erscheint die Prüfroutine schneller, da es nur einen Prüfdurchlauf gibt, in der Praxis brauch das Sichern und Zurückschreiben der bestehenden Daten allerdings wesentlich mehr Zeit. In meinem Beispiel anstatt nur etwas mehr als einer Stunde über 2,5 Stunden.
$ sudo badblocks -nsv /dev/sdc
Es wird nach defekten Blöcken im zerstörungsfreien Lesen+Schreiben-Modus gesucht
Von Block 0 bis 7812607
Es wird nach defekten Blöcken gesucht (zerstörungsfreier Lesen+Schreiben-Modus)
Es wird mit zufälligen Mustern getestet: 94.36% erledigt, 2:35:18 verstrichen. (0/0/0 Fehler)
Gefälschte USB-Sticks ermitteln
Einen Schritt weiter geht das Tool F3 oder etwas länger Fight Flash Fraud. Das Open-Source-Programm prüft ausführlich, ob ein Datenträger wirklich die Kapazität besitzt, die er vorgibt zu haben. Ein Thema, das leider immer noch aktuell ist, besonders wenn man super günstige Angebote aus dem Internet kauft. Um gefälschte USB-Sticks oder SD-Speicherkarten aufzudecken, müsst ihr das Programm aus dem Paketquellen installieren. Debian, Ubuntu, Fedora und Co. führen das Konsolenwerkzeug in den offiziellen Repositories, das Paket nennt sich in der Regel f3. Arch Linux führt das Programm nur im AUR, zur Installation braucht ihr daher einen AUR-Helper.
### Installation unter Arch Linux oder Manjaro:
$ yay -S f3
### Installation unter Debian, Ubuntu oder Raspberry Pi OS:
$ sudo apt install f3
Die Kommandos zum Prüfen von USB-Datenträgern lauten nun f3write, f3read und f3probe. Die ersten zwei Befehle müsst ihr in Kombination nutzen. Als Option übergebt ihr den Kommandos jeweils den Mountpunkt des Datenträgers. f3write schreibt nun so lange ein Gigabyte große Dateien auf den eingebundenen Datenträger, bis der Platz ausgeht. Anschließend prüft ihr mit f3read, ob die geschriebenen Daten auch wirklich wieder gelesen werden können. Falls es sich um einen gefälschten USB-Stick oder eine manipulierte SD-Speicherkarte handeln sollte, dann würde f3read korrupte Sektoren ausgeben. Bei dieser Prüfung bleiben alle Daten auf dem Datenträger erhalten, ihr müsst am Ende nur wieder die h2w-Dateien löschen, sonst habt ihr keinen Platz mehr auf dem Stick.
Ein wenig schneller arbeitet f3probe --destructive. Die Option --destructive ist optional, die beschleunigt die Aktion jedoch ganz wesentlich. Bei diesem Test beschreibt F3 nur die nötigsten Sektoren und kümmert sich auch nicht um eine Datensicherung. Da die Probe direkt auf die Hardware zugreif, gebt ihr als Parameter nicht den Mountpunkt sondern die Geräte-ID (hier /dev/sdg) an. Der Test mit meinem 4 GByte großen USB-2.0-Stick dauert so nur ein wenig mehr als sieben Minuten. Habt aber bei dieser Prüfung wieder im Hinterkopf, dass die Routine sämtliche Datenblöcke auf dem Datenträger überschreibt.
$ f3probe --destructive --time-ops /dev/sdg
[...]
Good news: The device `/dev/sdg' is the real thing
Device geometry:
*Usable* size: 3.73 GB (7831552 blocks)
Announced size: 3.73 GB (7831552 blocks)
Module: 4.00 GB (2^32 Bytes)
Approximate cache size: 0.00 Byte (0 blocks), need-reset=no
Physical block size: 512.00 Byte (2^9 Bytes)
Probe time: 7'17"
Operation: total time / count = avg time
Read: 2.73s / 4812 = 568us
Write: 7'13" / 3637313 = 119us
Reset: 1us / 1 = 1us
Sowohl Badblocks als auch F3 helfen beim Analysieren von Fehlern auf Datenträgern. Bei der Prüfung müsst ihr allerdings immer ein wenig Zeit mitbringen. Die ausführliche Analyse eines 8 GByte großen USB-Sticks kann schonmal zwei Stunden dauern, besonders wenn bei der Prüfung die Daten erhalten bleiben sollen und der USB-Stick nur mit dem langsamen USB-2.0-Protokoll arbeitet. Danach könnt ihr aber davon ausgehen, dass der USB-Stick oder die SD-Speicherkarte auch wirklich funktionieren und die Kapazität besitzen, die auf dem Aufdruck steht.
Ich sehe gerade, dass in zahlreichen Foren Nutzer mit Arch Linux auf dem Rechner aufschlagen, bei denen das Update vom über das AUR installiertem Spotify klemmt — Vermutlich dürften auch Manjaro und andere Arch-Derivate mit der Thematik kämpfen. Der Hintergrund ist dabei nicht weiter tragisch: Spotify hat einfach nur den GPG-Schlüssel geändert, mit denen die Entwickler ihre Pakete signieren. Dadurch scheitert der Download beziehungsweise die Überprüfung des Downloads und der AUR-Helper bricht das Update des Spotify-Pakets ab.
$ yay -Syu
[...]
:: PGP keys need importing:
-> F9A211976ED662F00E59361E5E3C45D7B312C643, required by: spotify
==> Import? [Y/n]
:: Importing keys with gpg...
gpg: Keine gültigen OpenPGP-Daten gefunden.
gpg: Anzahl insgesamt bearbeiteter Schlüssel: 0
-> problem importing keys
Um das Problem nun möglichst einfach zu lösen, macht ihr einfach ein Terminalfenster auf. Danach löscht ihr den obsoleten Schlüssel aus dem System und importiert den neuen GPG-Key der Entwickler von der Spotify-Webseite. Anschließend leert ihr den Cache des AUR-Helpers Yay (war zumindest bei mir nötig) und spielt dann alle anstehenden Updates ein. Diesmal sollte die Aktion ohne Fehler in einem Rutsch durchlaufen. Generell habe ich schon öfters festgestellt, dass Spotify gerne seine Schlüssel ändert, behaltet die Lösung daher also im Hinterkopf.
$ gpg --delete-key 8FD3D9A8D3800305A9FFF259D1742AD60D811D58
$ curl -sS https://download.spotify.com/debian/pubkey_5E3C45D7B312C643.gpg | gpg --import -
$ yay -Sc
$ yay -Syu
Überhaupt lohnt sich bei bockigen AUR-Paketen auch immer ein Blick auf die AUR-Seite des entsprechenden Pakets. Im Fall von Spotify wird die Lösung dort bereits ausführlich diskutiert. Schaut bei den Beiträgen auch immer auf das Datum des jeweiligen Kommentars: Oben unter „Pinned Comments“ sind immer wieder angestaubte Beiträge mit deutlich veralteten Informationen fixiert — je nach Engagement des Paketbetreuers. Erst unter den „Latest Comments“ findet ihr die neusten Kommentare mit aktuellen Hinweisen bei Problemen oder Schwierigkeiten.
Mit dem richtigen GPG-Schlüssel funktioniert das Update von Spotify unter Arch Linux wieder.