Es ist das erste Signal des Rates im Ringen um den sogenannten Datenomnibus: In einem ersten Positionierungsentwurf stellen sich die Mitgliedstaaten gegen mehrere Vorschläge der EU-Kommission, die von Datenschutz-Expert:innen kritisiert worden waren. Wir veröffentlichen den Zwischenstand.
Stop and Go für unterschiedliche Vorschläge im „Digital Omnibus“ – Gemeinfrei-ähnlich freigegeben durch unsplash.com Tanya Barrow
Die Europäische Union verhandelt derzeit über den „Digitalen Omnibus“. So wird ein Gesetzespaket genannt, mit dem die EU-Kommission Teile der europäischen Digitalregulierung überarbeiten will – und das möglichst schnell. Während die Kommission selbst lediglich von „technischen Änderungen“ und „Vereinfachung“ spricht, sehen viele andere auch einen Rückbau von Regulierung.
Während sich bei angestrebten Anpassungen der KI-Verordnung mögliche Kompromisse andeuten, sind vor allem weitreichende Änderungen im Bereich des Datenschutzes umstritten. Nun gibt es einen ersten Positionierungsentwurf des Rates zu diesem sogenannten Datenomnibus, der zentrale Vorschläge der EU-Kommission ablehnt oder abschwächt. Wir veröffentlichen das Dokument, über das erste Medien am Freitag berichteten.
Keine Neudefinition personenbezogener Daten
Eine von der EU-Kommission geplante Änderung der Definition personenbezogener Daten soll laut dem Ratspapier gestrichen werden. Der ursprüngliche Kommissionsvorschlag hätte zur Konsequenz, dass pseudonymisierte Daten unter Umständen nicht mehr von der Datenschutzgrundverordnung (DSGVO) erfasst wären. Das kritisierten unter anderem der Europäische Datenschutzausschuss und der EU-Datenschutzbeauftragte scharf. Sie sehen darin eine Schwächung des Schutzniveaus der DSGVO sehen und fürchten Rechtsunsicherheiten.
Die Mitgliedstaaten kommen anscheinend zu einer ähnlichen Einschätzung. Laut dem Verhandlungsstand des Rates sollen statt einer geänderten Definition lieber Richtlinien des Europäischen Datenschutzausschusses klären, wann pseudonymisierte Daten möglicherweise nicht der DSGVO unterliegen. Wegfallen soll auch eine neue Regel, die der EU-Kommission ermöglicht hätte, per Durchführungsakt Standards zu setzen und so die Deutungshoheit über datenschutzrechtliche Auslegungsfragen zu erlangen.
Auch einen Kommissionsvorschlag, voll-automatisierte Entscheidungen unter bestimmten Umständen zu erlauben, will der Rat streichen. Diese sind nach der DSGVO bislang verboten und sollen es dem Papier zufolge bleiben. Das Papier der Mitgliedstaaten übernimmt jedoch weniger strittige Vorschläge der Kommission, etwa um Meldewege bei IT-Sicherheitsvorfällen zu vereinfachen.
Konkretisieren will der Rat eine sehr breit gefasste Regel, die es Datenverarbeitern ermöglichen würde, Auskunfts- oder Löschanfragen von Betroffenen sehr leicht abzulehnen. Dies soll dem Papier zufolge nur noch dann möglich sein, wenn Betroffene eine große Anzahl identischer oder weitgehend ähnlicher Anfragen einreichen und dies mit der alleinigen Absicht tun, dem Verantwortlichen Schaden zuzufügen.
Wo steht Deutschland?
Das Dokument ist ein erster Vorschlag der zypriotischen Ratspräsidentschaft und beruht auf Beratungen der Mitgliedstaaten in der Arbeitsgruppe Vereinfachung. Bevor der Rat seine Position beschließt, wird der Arbeitsstand in der Gruppe weiter diskutiert und in weiteren Gremien beraten werden, so etwa im ranghöheren Ausschuss der Ständigen Vertreter. Es handelt sich also nur um ein erstes Signal, aber dieses fällt deutlich aus.
Sollte der Digitale Omnibus, der ja eigentlich nur Vereinfachungen vornehmen soll, am Ende ohne größere Reform der DSGVO verabschiedet werden, bedeutet es nicht, dass diese vom Tisch sind. Tatsächlich hatte die Kommission bereits angedeutet, dass ein für später im Jahr geplanter Fitness-Check der Digitalregulierung der Rahmen für eine größere Datenschutzreform sein könnte.
Der Datenomnibus wird nun zunächst weiter im EU-Parlament und im Rat diskutiert. Die nächsten Beratungen der Ratsarbeitsgruppe Vereinfachung finden an diesem Freitag statt. Dort wird das Feedback der Mitgliedstaaten auf den Positionsentwurf besprochen.
Deutschland gehört zu den Ländern, die sich hier gegen den Vorschlag der Ratspräsidentschaft und hinter die Deregulierungspläne der Kommission stellen könnten. Das deutsche Digitalministerium hatte die EU-Kommission im letzten Jahr zu ihren weitreichenden Vorschlägen ermutigt, unter anderem mit einem Positionspapier, das wir veröffentlicht haben. Darin regte Deutschland unter anderem weitreichende Einschränkungen von Betroffenenrechte an.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Unter Hochdruck will die EU Teile ihrer Digitalregulierung überarbeiten. Während der AI Act auf den letzten Metern noch um ein Verbot sexualisierter Deepfakes ergänzt werden könnte, treten beim Datenomnibus zwei wichtige EU-Institutionen auf die Bremse. Die neuesten Entwicklungen im Überblick.
Zumindest teilweise ist der „Digital Omnibus“ der EU mit hoher Geschwindigkeit unterwegs – Gemeinfrei-ähnlich freigegeben durch unsplash.com Gen Pol
Am 19. November 2025 präsentierte die Europäische Kommission den sogenannten „Digitalen Omnibus“: Mit zwei Gesetzen will die EU ihre Digitalregulierung überarbeiten und auf einen Schlag zahlreiche bestehende Gesetze ändern. Die Kommission will mit dem Paket Regeln vereinfachen, Bürokratie abbauen und so die Wettbewerbsfähigkeit Europas steigern.
Das erste dieser Gesetze, das die Datenschutzgrundverordnung (DSGVO), mehrere Datennutzungsgesetze und die Meldung von Cyber-Vorfällen betrifft, wird „Datenomnibus“ genannt. Das zweite Gesetz, welches die KI-Verordnung ändert, heißt „KI-Omnibus“. Für beide Vorhaben hat die Kommission ein hohes Tempo vorgegeben, die Änderungen sollen so schnell wie möglich beschlossen werden. Während dies beim KI-Omnibus, der unter anderem Teile der europäischen KI-Verordnung aufschieben soll, realistisch erscheint, dürften sich die Verhandlungen um den Datenomnibus deutlich länger hinziehen.
Sollen sexualisierte Deepfakes verboten werden?
Für den KI-Omnibus sind im Parlament zwei Ausschüsse verantwortlich: der Ausschuss für Binnenmarkt und Verbraucherschutz (IMCO) und der Ausschuss für bürgerliche Freiheiten, Justiz und Inneres (LIBE). Daher gibt es in diesem Fall auch zwei federführende Abgeordnete, die sogenannten Berichterstatter:innen: Michael McNamara ist Teil der Fraktion der Liberalen, Arba Kokalari gehört der konservativen EVP an, zu der auch CDU/CSU gehören.
Sie haben am 4. Februar gemeinsam ihren ersten Berichtsentwurf vorgelegt. Dieser beschreibt, wie sie die KI-Verordnung im Vergleich zum Vorschlag der EU-Kommission verändern wollen. Die verantwortlichen Abgeordneten anderer Fraktionen, die sogenannten Schattenberichterstatter:innen, haben bis zum 12. Februar ihre Änderungswünsche vorgelegt. Diese sind noch nicht öffentlich.
Bekannt ist jetzt schon, dass derzeit diskutiert wird, ob die Erstellung von sexualisierten Deepfakes im Rahmen des Omnibusses verboten werden soll – und unter welchen Umständen. Nach dem Skandal um Elon Musks Chatbot Grok, mit dem Nutzer:innen unfreiwillige Nacktbilder von Frauen und Minderjährigen erstellt haben, gibt es dafür gerade viel politischen Willen, sowohl im Parlament als auch unter den Mitgliedstaaten. Wie ein solches Verbot ausgestaltet werden könnte, ist jedoch umstritten.
Bei den Verhandlungen wird auch diskutiert, wer die Verantwortung für KI-Schulungen haben soll – die Anbieter der KI-Systeme oder die Regierungen. Außerdem soll entschieden werden, ob die verschobenen Fristen für Hochrisiko-Systeme fest oder flexibel sein werden. Dass sie überhaupt verschoben werden, scheint unter den Verhandelnden niemand mehr anzufechten. Ein weiteres Thema ist die Zentralisierung der Aufsicht im KI-Büro der EU-Kommission und das KI-Training mit sensiblen Daten, um Verzerrungen zu vermeiden. Ebenfalls besprochen werden mögliche Ausnahmen im Transparenzregister für KI-Systeme.
KI-Omnibus könnte bald schon am Ziel sein
Bereits nächste Woche startet im Parlament die Verhandlung, deren Ziel ein finaler Bericht ist. Es ist vorgesehen, dass die beiden Ausschüsse am 18. März darüber abstimmen. Damit würde dann die Parlamentsposition stehen und wäre bereit für den sogenannten Trilog mit der EU-Kommission und den Mitgliedstaaten.
Letztere erarbeiten im Moment ebenfalls ihre Position im Rat der Europäischen Union. Derzeit finden die Gespräche auf Ebene der Arbeitsgruppe „Vereinfachung“ statt. Es gibt bereits zwei Entwürfe. Wenn der Text final ist, wird er an die Diplomat:innen im „Ausschuss der Ständigen Vertreter“ gegeben. Auf der höchsten Ebene ist der Rat für Allgemeine Angelegenheiten für den KI-Omnibus verantwortlich.
Das Steuer hat dabei die derzeitige Ratspräsidentschaft Zypern in der Hand. Sie hat bereits angekündigt, den KI-Omnibus mit Priorität zu behandeln. Und das nicht ohne Grund: Schließlich sollen im Omnibus die Fristen für Hochrisiko-KI-Systeme angepasst werden, die eigentlich ab dem 2. August 2026 gelten würden. Der Omnibus muss daher spätestens bis zu diesem Datum in Kraft treten.
Insgesamt scheinen sich Rat und Parlament beim KI-Omnibus bisher relativ einig zu sein. Sie tendieren in vielen Punkten dazu, zum ursprünglichen Text der KI-Verordnung zurückzugehen. Unterschiede gibt es selbstverständlich in den Details.
Institutionen warnen vor Datenomnibus
Unübersichtlicher und umstrittener ist die Lage beim Datenomnibus. Während die Zusammenlegung von Datennutzungsgesetzen oder die Vereinfachung der Meldewege bei IT-Sicherheitsvorfällen für relativ wenig Aufregung gesorgt haben, ist um die Datenschutzaspekte des Vorhabens eine heftige Debatte entbrannt.
De EU-Kommission behauptet weiter steif und fest, lediglich technische Änderungen vorgeschlagen zu haben, die das Datenschutzniveau in der EU nicht verändern würden. Inzwischen mehren sich jedoch die Stimmen, die sagen: Vorschläge wie eine erleichterte Nutzbarkeit von Daten für KI, Einschränkungen von Betroffenenrechten oder eine Änderung der Definition personenbezogener Daten würde an Grundpfeilern des Datenschutzes rütteln.
In diesen Chor hat sich vergangene Woche auch der Europäische Datenschutzausschuss (EDSA) eingereiht, in dem die nationalen Datenschutzbehörden der EU zusammenarbeiten. „Einige vorgeschlagene Änderungen geben Anlass zu erheblichen Bedenken, da sie das Schutzniveau für Einzelpersonen beeinträchtigen, Rechtsunsicherheit schaffen und die Anwendung des Datenschutzrechts erschweren können“, heißt es in einer gemeinsamen Erklärung des EDSA mit dem Europäischen Datenschutzbeauftragten Wojciech Wiewiórowski.
Ehemalige Meta-Lobbyistin verhandelt über Datenschutz
Zwar begrüße man einige Vorschläge, die zu tatsächlichen Vereinfachungen führen. Darunter falle etwa eine Anhebung des Risikoschwellenwerts, ab dem eine Datenschutzverletzung der zuständigen Datenschutzbehörde gemeldet werden muss, oder die Verlängerung der Frist für die Meldung von Datenpannen. Auch Vorschläge zu Vereinfachungen bei Cookie-Bannern begrüßen die Datenschützer:innen.
Deutlich länger ist jedoch die Liste der gravierenden Mängel, die die Datenschützer:innen ausmachen. Allen voran kritisieren die Behörden die vorgeschlagene Neudefinition personenbezogener Daten, die pseudonymisierte Daten unter Umständen von der DSGVO ausnehmen würde. Dazu heißt es von der Vorsitzenden des Europäischen Datenschutzausschusses, Anu Talus: „Wir fordern die beiden gesetzgebenden Organe jedoch nachdrücklich auf, die vorgeschlagenen Änderungen der Definition personenbezogener Daten nicht anzunehmen, da sie den Schutz personenbezogener Daten erheblich schwächen könnten.“
Was die beiden angesprochenen Organe, das Europäische Parlament und der Rat der Mitgliedstaaten, mit dem Input der Datenschutz-Expert:innen anfangen werden, ist derzeit noch ziemlich offen. Der Datenomnibus wird zwar in den legislativen Prioritäten für 2026 genannt, auf welche sich die drei EU-Institutionen Ende des Jahres einigten. Das bedeutet: Das Vorhaben soll eigentlich noch in diesem Jahr abgeschlossen werden. Eine Positionierung des Rates ist nach Auskunft von Beobachter:innen in den nächsten Monaten allerdings nicht zu erwarten.
Im Parlament stellt man sich ebenfalls auf langwierige und zähe Verhandlungen ein. Hier teilen sich auch beim Datenomnibus zwei Ausschüsse die Federführung. Während im LIBE-Ausschuss für Bürgerliche Freiheiten die Sozialdemokratin Marina Kaljurand Berichterstatterin für das Thema ist, hat im Industrieausschuss (ITRE) Aura Salla das Ruder übernommen. Die finnische Politikerin von der konservativen Europäischen Volkspartei war von 2020 bis 2023 Chef-Lobbyistin des US-Tech-Konzerns Meta in Brüssel. Mit Blick auf den Datenomnibus sagte sie im Januar auf einer Veranstaltung: „Wir müssen deregulieren, nicht nur vereinfachen.“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die EU-Kommission will pseudonymisierte Daten teilweise von der Datenschutzgrundverordnung ausnehmen. Jetzt äußert sich erstmals eine deutsche Datenschutzbeauftragte. Meike Kamp übt deutliche Kritik an den Plänen und glaubt, die Kommission habe ein Urteil des Europäischen Gerichtshofes missverstanden.
Wenn die Person dahinter nicht mehr erkannt werden kann, sollen Daten künftig nicht mehr von der DSGVO geschützt sein – Gemeinfrei-ähnlich freigegeben durch unsplash.com Oscar Keys
Die Berliner Datenschutzbeauftragte Meike Kamp hat sich kritisch zu Plänen der EU-Kommission für eine Anpassung der Datenschutzgrundverordnung positioniert. „Die EU-Kommission rüttelt an den Grundpfeilern des Datenschutzes“, sagte sie gestern auf einer Veranstaltung ihrer Behörde zum Europäischen Datenschutztag in Berlin. Kamp kritisierte insbesondere den Vorschlag, pseudonymisierte Daten unter Umständen von der Datenschutzgrundverordnung (DSGVO) auszunehmen.
Mit dem sogenannten digitalen Omnibus will die EU-Kommission Teile ihrer Digitalgesetzgebung in den Bereichen Daten, KI und IT-Sicherheit überarbeiten. Die Kommission betont, es gehe ihr bei dem Sammelgesetz nur um Vereinfachungen und eine Zusammenlegung sich überlappender Rechtsakte. Kritiker:innen wenden ein, dass es sich dabei auch um einen Rückbau von Schutzstandards und den Auftakt einer umfassenden Deregulierung handelt.
Tatsächlich enthält der Gesetzesvorschlag beides. Er fasst mehrere Datennutzungsgesetze zusammen und vereinfacht Meldewege für IT-Sicherheitsvorfälle. Gleichzeitig schiebt er aber auch zentrale Regeln der noch jungen KI-Verordnung auf. Im Datenschutzbereich sollen außerdem Auskunftsrechte von Betroffenen eingeschränkt werden und sensible personenbezogene Daten sollen leichter für das Training von KI-Modellen genutzt werden können. Ebenfalls enthalten sind neue Regeln für Cookie-Banner.
Wann gelten pseudonymisierte Daten als personenbezogen?
In der datenschutzrechtlichen Fachdebatte kristallisiert sich inzwischen vor allem ein Vorschlag als Streitpunkt heraus: Die Kommission will verändern, was überhaupt als personenbezogene Daten gilt. Genauer gesagt will sie erreichen, dass pseudonymisierte Daten unter bestimmten Umständen gar nicht mehr als personenbezogen gelten und somit nicht mehr der DSGVO unterliegen. Pseudonymisierung bedeutet, dass Daten sich nicht mehr einer Person zuordnen lassen, ohne weitere Informationen hinzuzuziehen. In der Praxis heißt das oft: Statt mit dem Namen Namen oder der Telefonnummer einer Person werden ihre Daten mit einer Nummer versehen, die als Identifikator fungiert. Durch komplexe Verfahren kann man die Re-Identifikation erschweren, doch bislang gelten auch pseudonymisierte Daten oft als personenbezogen. Jedenfalls so lange, bis eine Rückverknüpfung gänzlich ausgeschlossen ist, denn dann gelten sie als anonymisiert.
Die EU-Kommission will nun einen relativen Personenbezug einführen. Vereinfacht gesagt heißt das: Wenn jemand bei der Verarbeitung von pseudonymisierten Daten nicht ohne Weiteres in der Lage ist, die Person dahinter zu re-identifizieren, sollen die Daten nicht mehr als personenbezogen gelten. Bei der Weitergabe pseudonymisierter Daten sollen diese nicht allein deshalb als personenbezogen gelten, weil der Empfänger möglicherweise über Mittel der Re-Identifikation verfügt.
Die Neudefinition soll es erleichtern, Daten zu nutzen und weiterzugeben. Das soll Innovationen ermöglichen. Wie eine Analyse von Nichtregierungsorganisationen kürzlich gezeigt hat, hatten vor allem große US-Tech-Konzerne Schritte in diese Richtung vehement gefordert.
Ringen um EuGH-Urteil
Meike Kamp sieht darin eine gravierende Einschränkung der Datenschutzgrundverordnung, wie sie bei der Eröffnungsrede [PDF] der Veranstaltung ihrer Behörde zu den Themen Anonymisierung und Pseudonymisierung darlegte.
Verdeutlich hat sie ihre Befürchtung am Beispiel Online-Tracking. Denn bei der Versteigerung von Werbeplätzen für zielgerichtete Werbung im Internet werden pseudonymisierte Daten an zahlreiche Firmen verschickt. „Verfügen diese Stellen nun über die Mittel, die natürlichen Personen zu identifizieren, oder gilt das nur für die eine Stelle, die die Webseite betreibt?“, so Kamp. Mit dem digitalen Omnibus sei es jedenfalls schwer zu argumentieren, dass sie von der DSGVO umfasst werden.
Schon heute tun sich Datenschutzbehörden schwer damit, die komplexen Datenflüsse im undurchsichtigen Ökosystem der Online-Werbung zu kontrollieren und Datenschutzverstöße zu ahnden. Die Databroker-Files-Recherchen von netzpolitik.org und Bayerischem Rundfunk hatten erst kürzlich erneut gezeigt, dass unter anderem Standortdaten aus der Online-Werbung bei Datenhändlern angeboten werden und sich damit leicht Personen re-identifizeren lassen – auch hochrangige Beamte der EU-Kommission. Zahlreiche zivilgesellschaftliche Organisationen hatten in einem offenen Brief die Sorge geäußert, dass die Praktiken der außer Kontrolle geratetenen Tracking-Industrie legitimiert werden könnten.
Die EU-Kommission beruft sich bei ihrem Vorschlag auch auf jüngste Rechtsprechung des Europäischen Gerichtshofes (EuGH) zum Thema Pseudonymisierung. Kamp kritisierte, dass dies auf einer Fehlinterpretation oder selektiven Lesart eines Urteils beruhe. Tatsächlich habe das Gericht klargestellt, dass pseudonymisierte Daten nicht immer personenbezogen seien, so Kamp. Wohl aber führe laut EuGH bereits die potenzielle Re-Identifizierbarkeit bei einem künftigen Empfänger dazu, dass die Daten als personenbezogen gelten müssen.
Auch Alexander Roßnagel übt Kritik
Kamps Einlassung ist die erste klare Äußerung einer deutschen Datenschutzbeauftragten zu dem Streitthema. Dem Vernehmen nach teilen nicht alle ihre Kolleg:innen ihre kritische Auffassung zur Pseudonymisierungsfrage. Eine offizielle Positionierung der Datenschutzkonferenz, deren Vorsitz Meike Kamp bei der Veranstaltung gestern turnusgemäß an ihren baden-württembergischen Kollegen Tobias Keber abgegeben hat, wird deshalb mit Spannung erwartet. Auch der Europäische Datenschutzausschuss hat sich noch nicht zum digitalen Omnibus positioniert.
Auf einer anderen Veranstaltung am gestrigen Mittwoch äußerte jedoch bereits einer von Kamps Kollegen ebenfalls deutliche Kritik: Der hessische Datenschutzbeauftragte Alexander Roßnagel. Er bezeichnete den Pseudonymisierungsvorschlag der Kommission als zu undifferenziert, sodass die Gefahr bestehe, dass das Schutzniveau der DSGVO deutlich sinke. Roßnagel hatte vor seiner Amtsübernahme lange eine Professur für Datenschutzrecht inne und ist einer der anerkanntesten Datenschutzjuristen des Landes.
Während der Datenschutzaktivist Max Schrems auf der Veranstaltung der Europäischen Akademie für Datenschutz und Informationsfreiheit ebenfalls heftige Kritik äußerte, verteidigte Renate Nikolay die Vorschläge. Als stellvertretende Generaldirektorin der EU-Generaldirektion für Kommunikationsnetze, Inhalte und Technologien trägt sie maßgebliche Verantwortung für den digitalen Omnibus.
Nikolay beharrte darauf, dass die Kommission beim Thema Pseudonymisierung lediglich die Rechtsprechung des EuGH umsetze. Der Vorschlag senke das Schutzniveau der Datenschutzgrundverordnung nicht ab. Zudem sei nicht zu befürchten, dass Datenhändler sich auf den relativen Personenbezug berufen und sich somit der Aufsicht entziehen könnten.
Kamp: Lieber Pseudonymisierung voranbringen, als Begriffe aufzuweichen
Grundsätzlich zeigte sich die EU-Beamtin jedoch offen für Nachbesserungen am digitalen Omnibus. Die Kommission habe einen Aufschlag gemacht und es sei klar, dass dieser verbessert werden könne. Derzeit beraten das EU-Parlament und der Rat der Mitgliedstaaten über ihre Positionen zu dem Gesetzespaket. Es wird erwartet, dass die Beratungen aufgrund des hohen Drucks aus der Wirtschaft schnell vorangehen.
Die Botschaft der Berliner Datenschutzbeauftragten für die Verhandlungen ist jedenfalls klar: Der Vorschlag der EU-Kommission zur Pseudonymisierung ist „der falsche Weg“. Stattdessen sprach Kamp sich für eine Stärkung von Verfahren der Pseudonymisierung und Anonymisierung aus.
Wie das konkret aussehen, zeigte die Veranstaltung ihrer Behörde zu Anonymisierung und Pseudonymisierung. Dort stellten Forscher:innen und Datenschützer:innen Projekte aus der Praxis vor. So etwa einen Ansatz zur Anonymisierung von Daten beim vernetzen Fahren oder ein Projekt, das maschinelles Lernen mit anonymisierten Gesundheitsdaten ermöglicht. Kamps Fazit: „Statt Begrifflichkeiten aufzuweichen, sollten wir solide Pseudonymisierung wagen.“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Databroker verhökern die Standortdaten von Millionen Menschen in Frankreich. Neue Recherchen zeigen: Mit den angeblich nur zu Werbezwecken erhobenen Daten lässt sich dort sogar Personal von Geheimdiensten und Militär ausspionieren – inklusive Entourage des französischen Präsidenten.
Ein Name der Person steht nicht im Datensatz. Stattdessen steht dort ein Pseudonym. Eine Kette aus Ziffern und Buchstaben, fast als wäre man einmal mit dem Kopf über die Tastatur gerollt. Und mit diesem Pseudonym versehen sind Hunderte exakte Geo-Koordinaten in Frankreich. Legt man die Geo-Koordinaten auf eine Karte, wird sichtbar, wo die Person überall unterwegs war.
Das Bewegungsprofil verrät mehr, als es ein bloßer Name getan hätte.
So lässt sich etwa ablesen, dass die Person Zugang zum Élysée-Palast hat, dem Amtssitz des französischen Präsidenten. Sie war demnach auch in La Lanterne, einem Jagdschloss in Versailles, wo der derzeitige Amtsinhaber Emmanuel Macron gerne das Wochenende verbringt. Weitere Besuche der Person waren auf dem Militärflugplatz Villacoublay, wo Dienstreisen des Präsidenten mit dem Flugzeug beginnen und enden. Besucht hat die Person auch einen Stützpunkt der Republikanischen Garde, also jenem Polizeiverband, der unter anderem den Präsidenten bewacht.
Sogar eine private Wohnadresse lässt sich in den Daten erkennen. Hier häufen sich die Handy-Ortungen. Ab jetzt ist es leicht, die Person zu identifizieren. Es genügt ein Besuch vor Ort. Und voilà: Auf dem Briefkasten steht der Name eines Menschen, der einer simplen Online-Recherche zufolge für die französische Gendarmerie arbeitet. Ein weiteres online verfügbares Dokument bekräftigt die Verbindung zu Macron.
Um die Identität der Person zu schützen, gehen wir nicht näher auf das Dokument ein. Doch gemeinsam mit unseren Recherchepartnern haben wir zahlreiche weitere brisante Fälle in dem Datensatz gefunden. Sie zeigen erstmalig am Beispiel Frankreichs, dass der unkontrollierte Handel mit Werbe-Daten nicht nur die Privatsphäre von Millionen Menschen gefährdet, sondern auch die Sicherheit Europas.
Ortungen bei Geheimdiensten, Militär und Rüstungskonzernen
Standortdaten wie diese sind wertvolles Material für Spionage, gefundenes Fressen für fremde Geheimdienste. Die Daten stammen nicht aus einem Hack oder einem Leak, sondern von einem Databroker. Um solche Daten zu erhalten, muss man nur freundlich nachfragen – und keinen Cent bezahlen.
Databroker verkaufen solche Handy-Standortdaten von Millionen Menschen als Abonnement; Vorschau-Daten gibt es gratis. Für jeden Standort im Datensatz gibt es eine einzigartige Kennung, die sogenannte Werbe-ID. Handy-Nutzer*innen bekommen sie automatisch von Google und Apple zugewiesen. Sie ist wie ein Nummernschild fürs Handy und sorgt dafür, dass über Apps ausgeleitete Handy-Standortdaten miteinander verknüpft werden können, bis sie letztlich nicht mehr anonym sind. Allein im Gratis-Datensatz, der dem Recherche-Team vorliegt, stecken rund eine Milliarde Standortdaten von bis zu 16,4 Millionen Geräten in Frankreich.
Andere verdienen ihr Geld mit euren Daten, wir nicht!
Recherchen wie diese sind nur möglich durch eure Unterstützung.
Seit mehreren Monaten recherchiert Le Monde gemeinsam mit netzpolitik.org, Bayerischem Rundfunk und weiteren internationalen Partnern. Es geht um die Massenüberwachung mithilfe von Handy-Standortdaten, die angeblich nur zu Werbezwecken erhoben werden. Die Recherchen aus Frankreich sind der neuste Teil der Databroker Files, die seit Februar 2024 erscheinen.
All diese Recherchen zeigen: Kein Ort und kein Mensch sind sicher vor dem Standort-Tracking der Werbeindustrie. Um die Gefahr des Trackings anschaulich zu machen, hat sich Le Monde nun auf Handy-Ortungen fokussiert, die für die nationale Sicherheit von Frankreich relevant sind. So konnte das Team in mehreren Dutzend Fällen mit Sicherheit oder hoher Wahrscheinlichkeit Identität, Wohnort und Gewohnheiten von Angestellten sensibler Einrichtungen nachvollziehen. Dazu gehören Angestellte von Geheimdienst und Militär in Frankreich, der Spezialeinheit GIGN, die für Terrorismusbekämpfung zuständig ist, sowie Personal von Rüstungsunternehmen und Kernkraftwerken.
Besuche in der Deutschen Botschaft und beim Polo
Mehrere Bewegungsprofile aus dem französischen Datensatz haben sogar einen Bezug zu Deutschland. So zeigt ein Profil die Bewegungen einer Person, die möglicherweise als Diplomat*in arbeitet. Sie hat Zugang zur Rechts- und Konsularabteilung der deutschen Botschaft und zur Residenz des deutschen Botschafters in Paris. Die Handy-Ortungen zeigen eine Reise nach Verdun, inklusive Besuch von Museum und Gedenkstätten. Auch ein Abstecher zu einem Polofeld in Paris ist zu finden.
Aus dem Auswärtigen Amt heißt es, die Risiken durch Databroker seien bekannt. Die Mitarbeitenden würden regelmäßig zu den Risiken sensibilisiert – müssten aber gleichzeitig umfassend erreichbar sein.
Weitere Bewegungsprofile aus dem Datensatz konnte das Recherche-Team Angestellten von Rüstungsunternehmen zuordnen. Gerade wegen der militärischen Bedrohung durch Russland ist die europäische Rüstungsindustrie besonders dem Risiko von Spionage und Sabotage ausgesetzt. Im Datensatz finden sich etwa die Handy-Ortungen einer Person, die offenbar in hoher Position für den deutsch-französischen Rüstungskonzern KNDS tätig war. Zu den Produkten von KNDS gehören Panzer, Bewaffnungssysteme, Munition und Ausrüstung; das Unternehmen, das durch eine Fusion von Krauss-Maffei Wegmann und Nexter entstand, ist ein wichtiger Lieferant für die Ukraine.
Auf Anfrage teilt der Konzern mit, man sei sich der Notwendigkeit bewusst, Mitarbeitende für diese Themen zu sensibilisieren. Über ergriffene Maßnahmen wolle man jedoch nicht öffentlich sprechen.
Von „Sensibilisierung“ sprechen viele Organisationen, wenn man sie danach fragt, wie sie sich vor der Überwachung schützen wollen. So schreiben etwa die Pressestellen des französischen Verteidigungsministeriums und Inlandsgeheimdiensts DGSI auf Anfrage von Le Monde von der Sensibilisierung ihrer Angestellten. Mit Sensibilisierung – und zwar in Form einer Rundmail – hatten im November auch die Organe der Europäischen Union auf unsere Recherchen reagiert, die zeigten, wie sich mithilfe der Standortdaten Spitzenpersonal der EU in Brüssel ausspionieren lässt.
Und so ist es schier unvermeidbar, dass aller Sensibilisierung zum Trotz immer wieder Daten abfließen und in die Hände von Databrokern gelangen – selbst Standortdaten aus der Entourage des französischen Präsidenten.
Eine Gefahr für Europa
Auf Anfrage von Le Monde hat der Élysée-Palast selbst nicht reagiert. Zumindest für Präsident Macron dürfte das Thema jedoch nicht ganz neu sein. Denn im Jahr 2024 hatte Le Monde schon einmal Standortdaten von Menschen aus seinem Umfeld aufgespürt, und zwar über die Fitness-App Strava. Damit können Nutzer*innen etwa ihre Jogging-Routen tracken und online mit der Öffentlichkeit teilen, was Macrons Sicherheitspersonal unvorsichtigerweise getan hatte.
Der Unterschied: Damals ging es um den Umgang mit einer einzelnen Fitness-App. Die Databroker Files zeigen jedoch, wie sensible Handy-Standortdaten über einen großen Teil kommerzieller App abfließen können. Inzwischen liegen dem Recherche-Team mehrere Datensätze von mehreren Databrokern vor. Sie umfassen rund 13 Milliarden Standortdaten aus den meisten Mitgliedstaaten der EU, aus den USA und vielen weiteren Ländern.
Die Databroker Files zeigen auch, dass die DSGVO (Datenschutzgrundverordnung) gescheitert ist – mindestens in ihrer Durchsetzung. Der unkontrollierte Datenhandel bedroht nicht nur auf beispiellose Weise die Privatsphäre und informationelle Selbstbestimmung von Nutzer*innen, sondern in Zeiten erhöhter Spionagegefahr auch die Sicherheit Europas.
Im Zuge unserer Recherchen haben Fachleute aus Politik, Wissenschaft und Zivilgesellschaft wiederholt Konsequenzen gefordert. „Angesichts der aktuellen geopolitischen Lage müssen wir diese Bedrohung sehr ernst nehmen und abstellen“, sagte im November etwa Axel Voss (CDU) von der konservativen Fraktion im EU-Parlament, EVP. Die EU müsse entschieden handeln. „Wir brauchen eine Präzisierung der Nutzung der Standortdaten und somit ein klares Verbot des Handels mit besonders sensiblen Standortdaten für andere Zwecke.“ Weiter brauche es „eine europaweite Registrierungspflicht für Datenhändler und eine konsequente Durchsetzung bestehender Datenschutzregeln“.
EU könnte Datenschutz noch weiter abschwächen
Seine Parlamentskollegin Alexandra Geese von der Fraktion der Grünen/EFA sagte: „Wenn der Großteil der europäischen personenbezogenen Daten unter der Kontrolle von US-Unternehmen und undurchsichtigen Datenbrokern bleibt, wird es deutlich schwieriger, Europa gegen einen russischen Angriff zu verteidigen.“ Sie forderte: „Europa muss die massenhafte Erstellung von Datenprofilen verbieten.“
Statt die Gefahr einzudämmen, hat die EU-Kommission jedoch jüngst mit dem Digitalen Omnibus einen Plan vorgelegt, um den Datenschutz in Europa noch weiter zu schleifen. Konkret sollen demnach manche pseudonymisierten Daten nicht mehr als „personenbezogen“ gelten und deshalb den Schutz durch die DSGVO verlieren. Dabei zeigen die Databroker Files eindrücklich, wie intim und gefährlich die Einblicke durch angeblich pseudonyme Daten sein können.
Der EU stehen kontroverse Verhandlungen bevor. Teilweise oder weitgehende Ablehnung zu den Vorschlägen gab es bereits von den Fraktionen der Sozialdemokraten, Liberalen und Grünen im EU-Parlament. Zudem warnten mehr als 120 zivilgesellschaftliche Organisationen in einem offenen Brief vor dem „größten Rückschritt für digitale Grundrechte in der Geschichte der EU“.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
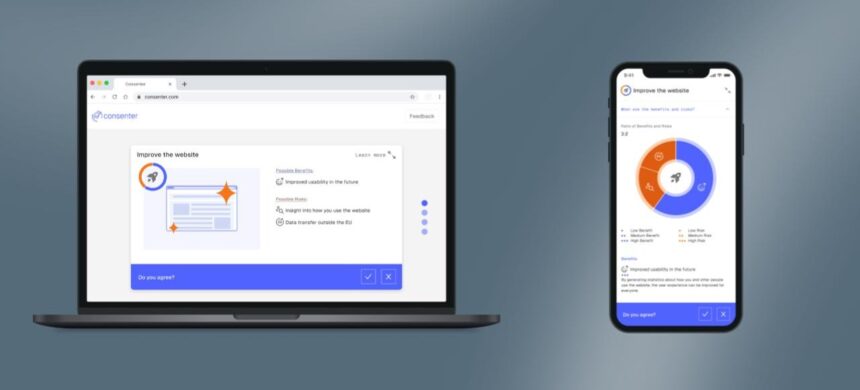
Maximilian von Grafenstein ist Professor für „Digitale Selbstbestimmung“ und hat mit seinem Team den ersten Einwilligungs-Agenten Deutschlands entwickelt. Das Tool namens „Consenter“ soll Nutzer:innen die Entscheidungsmacht im Datenschutz zurückgeben. In der neuen Folge versucht er, uns von dem Dienst zu überzeugen.
Gesprächspartner bei On The Record: Maximilian von Grafenstein
In der neuen Folge „On The Record“ spreche ich mit Maximilian von Grafenstein. Er ist Jurist, Historiker, Professor für „Digitale Selbstbestimmung“ an der Universität der Künste in Berlin und Teil des Einstein Center for Digital Future. Zusammen mit einem Team hat er in jahrelanger Forschung ein Tool entwickelt, von dem er sagt, dass es die Cookie-Krise lösen kann.
Denn hinter den nervigen Bannern auf Online-Websites steht ein Grundproblem der Datenschutzgrundverordnung: Das Instrument der informierten Einwilligung soll Nutzer:innen eigentlich informationelle Selbstbestimmung ermöglichen, doch es ist zur Farce verkommen. Die Browser-Erweiterung „Consenter“ soll das ändern. Sie ist ein sogenannter Einwilligungsdienst, der Nutzer:innen zu ihrem Recht verhelfen soll. Einfach, übersichtlich und gut informiert sollen Menschen damit entscheiden können, wem sie im Netz für welche Zwecke ihre Einwilligung geben – und wem nicht.
Ich bin skeptisch, dass das funktionieren kann. Aber ich bin auch neugierig, dass da jemand die Datenschutzgrundverordnung ernst nimmt und dabei auch noch verspricht, dass davon nicht nur Nutzer:innen, sondern auch Unternehmen profitieren würden. Im Podcast stellt Maximilian von Grafenstein „Consenter“ vor, wir diskutieren aber auch über Grundfragen der Datenschutzpolitik.
Übrigens: Das „Consenter“-Team sucht Website-Betreiber:innen – idealerweise mit einer größeren Nutzerschaft – die sich an einem Beta-Test des Tools beteiligen. Interessierte können sich per E-Mail an Maximilian von Gafenstein wenden: max.grafenstein@law-innovation.tech
So sieht Consenter aus - Alle Rechte vorbehalten UDK Berlin
Bei unserem Podcast „Off/On“ wechseln sich zwei Formate ab: Bei „Off The Record“ führen wir euch in den Maschinenraum von netzpolitik.org und erzählen Hintergründe zu unserer Arbeit. Bei „On The Record“ interviewen wir Menschen, die unsere digitale Gesellschaft prägen.
Unseren Podcast könnt ihr auf vielen Wegen hören. Der einfachste: in dem Player hier auf der Seite auf Play drücken. Ihr findet uns aber ebenso bei Apple Podcasts, Spotify und Deezer oder mit dem Podcatcher eures Vertrauens, die URL lautet dann netzpolitik.org/podcast.
Wie immer freuen wir uns über Kritik, Lob und Ideen, entweder hier in den Kommentaren oder per Mail an podcast@netzpolitik.org.
Links und Infos
Projektwebsite des Einwilligungsdienstes „Consenter“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Die Folgen des KI-Hypes für den Datenschutz sind schwer absehbar. Im Fall von Metas KI-Training zögern Aufsichtsbehörden, das Oberlandesgericht Köln gab dem Konzern sogar – fürs Erste – grünes Licht. Jura-Professorin Paulina Jo Pesch zeigt Schwächen des Urteils auf und fordert eine entschiedenere Durchsetzung der Datenschutzvorgaben.
Hinter weitverbreiteten KI-Anwendungen stehen generative Sprach- und Bildmodelle, die mit riesigen Datenmengen gefüttert werden, auch mit personenbezogenen Daten. Das Problem: Teile der Trainingsdaten, darunter personenbezogene, lassen sich aus vielen der Modelle extrahieren. Unter welchen Umständen sich ein Modell zu viel „merkt“ und wie sich das verhindern lässt, ist bislang wenig erforscht. Zugleich werden Extrahierungsmethoden immer besser. Anbieter*innen können bislang nicht verhindern, dass Modelle personenbezogene Trainingsdaten ausgeben. Auch Chatbots können personenbezogene Daten von anderen verraten.
Außerdem „halluzinieren“ die Modelle. Sie generieren also falsche Informationen, die nicht in den Trainingsdaten enthalten sind. Weil KI-Unternehmen diese nicht offenlegen, können Forscher*innen nicht zuverlässig messen, wann ein Modell Informationen erfindet und wann es unrichtige Trainingsdaten wiedergibt. Zuverlässige Methoden zur Vermeidung von Halluzinationen gibt es bisher nicht.
Werden personenbezogene Daten aus einem Modell extrahiert, kann für Betroffene gerade die Kombination aus „Erinnerung“ und „Halluzination“ gefährlich sein. Ein mit personenbezogenen Daten trainiertes Modell generiert unter Umständen Falschinformationen über sie. Gerade bei öffentlichen Modellen besteht das Risiko, dass Nutzer*innen diese Informationen unkritisch weiterverbreiten.
Meta fragt lieber nicht um Erlaubnis
Mit Llama (Large Language Model Meta AI) ist auch Meta an dem KI-Rennen beteiligt. Meta nutzt Llama für eigene KI-Funktionen wie Transkriptions- oder Suchfeatures auf Instagram, Facebook und WhatsApp sowie für Chatbots oder in KI-Brillen, die das Unternehmen anbietet. Außerdem stellt Meta seine Modelle anderen zur Nutzung bereit. So können etwa Forscher*innen die Modelle testen oder Unternehmen auf Basis von Llama KI-Dienstleistungen oder -Produkte anbieten.
Im Juni 2024 informierte Meta die Nutzer*innen von Instagram und Facebook über eine Aktualisierung seiner Datenschutzrichtlinie. Diese Aktualisierung ließ Metas Vorhaben erkennen, seine KI-Modelle mit Nutzer*innendaten zu trainieren. Die Nutzer*innen konnten dem zwar widersprechen, die Widerspruchsmöglichkeit war jedoch schwer auffindbar.
Inzwischen hat der Konzern damit begonnen, seine KI mit den Daten europäischer Nutzer*innen zu trainieren. Unklar ist weiterhin, welche Daten dafür genau genutzt werden. Meta stellt im Vergleich zu anderen KI-Unternehmen zwar mehr Informationen über das Training mit Social-Media-Daten bereit. Diese Informationen haben sich aber immer wieder verändert und lassen Fragen offen.
Das betrifft insbesondere den Umgang mit sensiblen Daten. Bei Llama handelt es sich um ein multimodales Sprachmodell, das neben Texten auch Bilder, Videos und Tondateien verarbeitet. Der für das Training genutzte Social-Media-Content umfasst damit etwa auch Fotos der Nutzer*innen. Metas Datenschutzinformationen verweisen auf öffentliche Inhalte wie Beiträge, Kommentare und Audiospuren.
Inzwischen heißt es in den Datenschutzinformationen, dass auch Daten von Drittpartner*innen und KI-Interaktionen für die KI-Entwicklung genutzt würden. Als Beispiele für KI-Interaktionen nennt Meta Nachrichten, die Nutzer*innen oder andere Personen von der KI erhalten, mit ihr teilen oder an diese senden.
Diese Angaben schließen private Sprachnachrichten und Transkriptionen nicht aus. Metas Umschreibung passt auch auf Chatverläufe mit Chatbots. Solche Chatverläufe können besonders sensible Daten enthalten, wenn etwa Chatbots für intime Gespräche zu mentaler Gesundheit oder parasoziale romantische Beziehungen genutzt werden.
Verbraucherzentrale scheitert vor Gericht
Um den Beginn des Trainings zu verhindern, hat die Verbraucherzentrale Nordrhein-Westfalen im Mai 2025 einen Eilantrag beim Oberlandesgericht (OLG) Köln gestellt. Sie argumentierte insbesondere, dass Meta das Training nicht auf eine wirksame Rechtsgrundlage stützen könne, ist mit dem Eilantrag jedoch gescheitert. Das Urteil und Einblicke in die mündliche Verhandlung in Köln offenbaren erhebliche Mängel.
Meta hatte sich entschieden, keine Einwilligungen einzuholen, sondern beruft sich auf ein berechtigtes Interesse an der Nutzung der Daten für KI-Training. Die Verbraucherzentrale hält das für unzureichend, doch das Gericht folgt Metas Argumentation in seinem Urteil. Nach der Datenschutzgrundverordnung (DSGVO) können berechtigte Interessen die Verarbeitung personenbezogener Daten rechtfertigen, solange die Interessen Betroffener nicht schwerer wiegen. Dabei müssen diese der Datenverarbeitung aber widersprechen können.
Die Verbraucherzentrale NRW hat darauf hingewiesen, dass nicht alle Betroffenen widersprechen können. Facebook- und Instagram-Beiträge enthalten zuhauf personenbezogene Daten von Nicht-Nutzer*innen. Die Widerspruchsfunktion steht aber nur Nutzer*innen offen. Das Gericht ignoriert diesen Einwand. Zudem behauptet es ohne Begründung und trotz gegenteiliger Hinweise, Meta erfülle die Anforderungen der DSGVO an den Schutz von Minderjährigen.
Das Gericht halluziniert niedrige Risiken herbei
Berechtigte Interessen geben außerdem keine Rechtsgrundlage für Verarbeitungen her, die für Betroffene zu riskant sind. Das OLG Köln behauptet, die Risiken für Nutzer*innen seien gering. Dabei legt das Urteil nahe, dass die Richter*innen nicht verstanden haben, was Meta trainiert. Das Wort „Llama“ taucht im gesamten Urteil nicht auf. Auch beschreibt das Gericht keine Anwendungsszenarien.
Auf diese kommt es aber entscheidend an. Ein Transkriptionsfeature gibt wahrscheinlich keine extrahierbaren Daten aus. Aus Llama selbst werden jedoch sicher Daten extrahiert. Forscher*innen wenden Extrahierungsmethoden auf alle bekannten Modelle an. Je nachdem, welche Arten von Daten wie gut extrahierbar sind, könnte es dabei versehentlich auch zu Datenlecks kommen.
Gerichte prüfen in Eilverfahren die Rechtslage nur „kursorisch“, also nicht im Detail. Das OLG Köln reiht dabei aber mit großem Selbstbewusstsein Behauptungen aneinander, die aus Sicht der Datenschutzforschung haltlos sind. Selbst wenn Metas Training transparent genug wäre, fehlt es an tragfähigen Forschungsergebnissen für die Einschätzung des Gerichts.
Ein grober Fehler des Urteils betrifft besondere Kategorien personenbezogener Daten. Das sind sensible Daten, die die DSGVO besonders schützt, zum Beispiel Daten über Race, religiöse Anschauungen oder sexuelle Orientierungen. Social-Media-Daten enthalten viele solcher Daten. Besondere Kategorien personenbezogener Daten dürfen nicht auf Basis berechtigter Interessen verarbeitet werden, sondern nur unter strengeren Voraussetzungen, in vielen Fällen nur aufgrund von Einwilligungen. Das OLG Köln stört sich daran nicht.
Stattdessen behauptet das Gericht, dass die Anwendung der besonderen Schutzanforderungen nicht geboten sei. Das Urteil stellt hier wieder auf ein nicht weiter begründetes geringes Risiko ab. Dabei kommt es gerade im Bereich des maschinellen Lernens leicht zu unbemerkten Modellbias, also zu systematischen Fehleinschätzungen, die zum Beispiel zu rassistischer Diskriminierung führen. Besondere Kategorien personenbezogener Daten bergen dabei potenziell besonders hohe Risiken.
Bedenkliche Informationslage
Bedenklich ist zudem die Informationslage, auf die sich das Gericht stützt. In diesem Fall sind das vor allem die Angaben von Meta selbst. Das ist in einem Eilverfahren an sich nicht zu beanstanden – weil es schnell gehen muss, gelten geringere Beweisanforderungen. Gerichte arbeiten daher mit eidesstattlichen Versicherungen, formellen Erklärungen der Parteien. Um Falschangaben vorzubeugen, sind falsche eidesstattliche Versicherungen nach dem Strafgesetzbuch strafbar.
Das Urteil stellt entscheidend auf eidesstattliche Versicherungen von Metas Produktmanager für generative KI ab. Zwei in der mündlichen Verhandlung in Köln anwesende Personen berichten allerdings, dass die Versicherungen nie formgerecht abgegeben worden sind. (Die Autorin hat von zwei in der Verhandlung in Köln anwesenden Personen Informationen zum Ablauf der mündlichen Verhandlung und dabei getroffenen Aussagen des Gerichts erhalten. Eine der Personen ist seitens der klagenden Verbraucherzentrale am Verfahren beteiligt, die andere Person hat den Prozess beobachtet, ohne daran beteiligt zu sein.)
Eidesstattliche Versicherungen müssen mündlich oder im Original mit händischer Unterschrift abgegeben werden. Selbst wenn die Erklärungen von Meta formgerecht wären, hätte sich das OLG Köln besser nicht darauf verlassen. Es gibt zwar keine Anzeichen dafür, dass diese Falschangaben enthalten. Durch das deutsche Strafgesetzbuch wäre deren Richtigkeit aber nicht abgesichert: Falls der in Kalifornien ansässige Manager nicht einreisen will, hätten Falschangaben keine strafrechtlichen Folgen für ihn.
Zudem legt das Urteil nahe, dass Metas Erklärungen inhaltlich dünn sind. Sie bestätigen etwa das Funktionieren der Widerspruchsfunktion. Eine Pressemitteilung der für Meta zuständigen irischen Datenschutzbehörde (Data Protection Commission, DPC) zeigt jedoch, dass die Behörde Meta zur Nachbesserung der Widerspruchsfunktion aufgefordert hat. Es bleibt somit zweifelhaft, ob Widersprüche in der Vergangenheit einfach genug möglich waren und funktioniert haben.
Datenschutzbehörden lassen Meta erst mal machen
Auch die Pressemitteilung der irischen Datenschutzbehörde und der Umgang des Gerichts damit verdienen besondere Aufmerksamkeit. Die für ihre Nachsicht gegenüber Datenkonzernen bekannte Behörde hat die Pressemitteilung am Vorabend der mündlichen Verhandlung in Köln veröffentlicht. Sollte die Behörde sich etwa mit Meta abgestimmt und so das Verfahren beeinflusst haben?
Das OLG Köln hat nach Berichten Anwesender schon in der mündlichen Verhandlung signalisiert, der Rechtsauffassung der irischen Behörde wahrscheinlich folgen zu müssen, warum auch immer das Gericht sich an deren Einschätzung auch nur lose gebunden fühlt. Das ist nicht nur im Hinblick auf die Gewaltenteilung bedenklich. Die Pressemitteilung enthält auch keinerlei Rechtsauffassung zur Frage nach der Datenschutzkonformität, der das Gericht folgen könnte. Sie enthält schlicht gar keine rechtliche Einschätzung. Es heißt lediglich, Meta habe in Absprache mit der Behörde Maßnahmen zur Verbesserung des Datenschutzes ergriffen und verfolge die Umsetzung weiter.
Aus der Pressemitteilung wird ersichtlich, dass die irische Behörde Meta nur beraten hat. Das war dem OLG Köln auch von Metas Hauptaufsichtsbehörde in Deutschland, dem Hamburger Datenschutzbeauftragten, bekannt. Im Urteil heißt es ausdrücklich, die Behörde habe Meta das Training „bislang“ nicht untersagt und beobachte derzeit die Folgen der Trainings.
Der Hamburger Datenschutzbeauftragte hatte im Juli 2024 die Datenschutzauswirkungen des Trainings generativer Sprachmodelle noch unterschätzt. Nach Berichten aus der mündlichen Verhandlung hat er angesichts seiner Einblicke in Metas Training diese Auffassung zurückgenommen, erhebliche Datenschutzbedenken geäußert und zunächst sogar ein eigenes Verfahren gegen Meta angekündigt. Außerdem berichtete er, dass die irische Behörde plane, ein Verletzungsverfahren im Oktober einzuleiten. Das spricht dafür, dass europäische Datenschutzbehörden von Verstößen wissen, Meta aber zunächst gewähren lassen.
Wider den KI-Hype
Die Bedeutung des Kölner Verfahrens weist über Meta und über Deutschland hinaus. Das Urteil und die Vorgänge im Prozess legen nahe, dass europäische Gerichte und Aufsichtsbehörden bei KI dem Ansatz „Abwarten und Teetrinken“ folgen. Es lässt sich nur spekulieren, welche Rollen hier der Druck des KI-Hypes, Innovationspläne der EU oder auch blanke Naivität spielen.
Dabei macht die DSGVO nicht nur klare Vorgaben an KI-Unternehmen, sondern bietet diesen auch ausreichende Möglichkeiten, sich an die Vorgaben zu halten. Demnach müssen KI-Unternehmen die Datenschutzkonformität ihrer Vorhaben begründet nachweisen. Sie dürfen ihre Modelle trainieren und testen – allerdings nur zu reinen Forschungszwecken und ohne die KI in der Praxis einzusetzen – und damit blind auf die Menschheit loszulassen. Gerichte und Aufsichtsbehörden sollten diese Vorgaben durchsetzen, anstatt sich dem KI-Hype zu beugen.
Prof. Dr. Paulina Jo Pesch ist Juniorprofessorin für Bürgerliches Recht sowie das Recht der Digitalisierung, des Datenschutzes und der Künstlichen Intelligenz am Institut für Recht und Technik der Friedrich-Alexander-Universität Erlangen-Nürnberg. Sie koordiniert das vom Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR) geförderte interdisziplinäre Forschungsprojekt SMARD-GOV, das Datenschutzaspekte großer Sprachmodelle erforscht.
Eine englischsprachige Langfassung der Analyse des Verfahrens sowie eines weiteren Verfahrens beim OLG Schleswig-Holstein ist im CR-online blog erschienen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen. Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
EU-weit soll die Einführung einer sogenannten ID-Wallet vorangetrieben werden, mit der sich Menschen digital ausweisen können und die dafür deren Identitätsdaten speichert. Auch juristische Personen sollen die Möglichkeit bekommen, diese ID-Wallets zu nutzen. Für den Gesetzesvorschlag der EU-Kommission gibt es jedoch keineswegs nur Lob – im Gegenteil.
In der Europäischen Union trat 2014 die Verordnung über elektronische Identifizierung und Vertrauensdienste für elektronische Transaktionen im Binnenmarkt in Kraft, die nun reformiert werden soll. Diese überarbeitete eIDAS-Verordnung soll allen EU-Bürgern die Möglichkeit zu einer digitalen Identität schmackhaft machen, die den Namen „European Digital Identity Wallet“ bekommen wird. Die ID-Wallet soll jeweils in der Hoheit der einzelnen EU-Mitgliedstaaten bereitgestellt werden, aber eine überall kompatible EU-weite Lösung sein.
Der Entwurf der EU-Kommission zur eIDAS-Neuregelung vom Juni 2021 (eIDAS: electronic IDentification, Authentication and trust Services) hat in der Wirtschaft überwiegend positives Feedback bekommen, er trifft jedoch auf breite Kritik und Nachbesserungswünsche von Bürgerrechtsorganisationen, Datenschützern und Experten für IT-Sicherheit. Die Kritik ist nicht ganz neu, schon im Juli 2021 (pdf) hatte der Europäische Datenschutzbeauftragte Schwachpunkte der geplanten Reformierung aufgezeigt, die aus Sicht des Datenschutzes bestehen. Eine öffentliche Konsultation hatte im Sommer zu Stellungnahmen aufgefordert.
Es existieren in Europa teilweise schon jahrelang Lösungen für nationale elektronische Identitäten, aber mit Dänemark, Deutschland, Schweden und Ungarn haben noch vier Staaten inkompatible Eigenkreationen. Die nun zur Überarbeitung vorgesehene Verordnung hat eine europaweit nutzbare ID-Wallet zum Ziel.
Von der Leyen verspricht eine sichere europäische elektronische Identität
Die Präsidentin der Europäischen Kommission, Ursula von der Leyen, hatte höchstselbst in ihrer Rede zur Lage der Union 2020 für die einheitliche ID-Wallet geworben. Sie beschrieb, dass niemand in der Praxis wissen können, was mit den eigenen Daten passiere und wie aber der geplante neue digitale EU-Identitätsspeicher die Kontrolle zurückbrächte:
Jedes Mal, wenn eine Website uns aufgefordert, eine neue digitale Identität zu erstellen oder uns bequem über eine große Plattform anzumelden, haben wir in Wirklichkeit keine Ahnung, was mit unseren Daten geschieht. Aus diesem Grund wird die Kommission demnächst eine sichere europäische digitale Identität vorschlagen. Eine, der wir vertrauen und die Bürgerinnen und Bürger überall in Europa nutzen können, um alles zu tun, vom Steuern zahlen bis hin zum Fahrrad mieten. Eine Technologie, bei der wir selbst kontrollieren können, welche Daten ausgetauscht und wie sie verwendet werden.
Ganz so rosig wie in von der Leyens schwärmenden Worten wird die Umsetzung der ID-Wallet-Idee derzeit nicht bewertet, jedenfalls nicht aus Sicht von Datenschützern und IT-Sicherheitsfachleuten. Eine öffentliche Anhörung zu eIDAS beim Parlamentsausschuss für Industrie, Forschung und Energie brachte am Donnerstag Experten für eine Diskussion zusammen. Wojciech Wiewiórowski, der Europäische Datenschutzbeauftragte, erneuerte dort gleich zu Beginn seine Kritik, warnte vor Gefahren und forderte Nachbesserungen.
Ein weiterer der angehörten Kritiker der geplanten Verordnungsreform war Thomas Lohninger, Geschäftsführer des Vereins epicenter.works aus Österreich und Vizepräsident von European Digital Rights. Eine Konsequenz der neuen digitalen Brieftasche könne ein für die Privatsphäre von Menschen gefährliches Szenario sein, vor dem Lohninger auch in seiner Stellungnahme (pdf) warnt: Gezielte Werbung könnte mit der staatlich garantierten Identität gekoppelt werden. Die Werbewirtschaft wüsste dann quasi mit staatlichem Stempel, mit wem sie es namentlich zu tun hat und wem konkret sie Werbung unterjubelt.
Thomas Lohninger, Vizepräsident von EDRi.
Lohninger betonte, es fehle an „Schutzmaßnahmen gegen Missbrauch bei Tracking, Profiling und gezielter Werbung“. Hier müsse man dringend nachbessern. Es bestehe keine besondere Eile bei der Gesetzgebung, insofern plädiere er dafür, diesen Mangel zu beseitigen. Er rate auch zu einer Art Negativ-Liste, in der verständlich festgehalten werden solle, wofür die Daten der ID-Wallet keinesfalls verwendet werden dürfen. Auf jeden Fall müsse verhindert werden, dass mit der ID-Wallet am Ende nur die Tracking- und Werbewirtschaft und insbesondere auch die großen außereuropäischen Tech-Konzerne gestärkt werden.
Informationssammlung beim ID-Wallet-Herausgeber
Ein anderer potentiell gefährlicher Datenmissbrauch droht wegen der Daten, die bei der Nutzung des Identitätsspeichers beim Wallet-Herausgeber anfallen. Die Vorschläge der EU-Kommission schreiben zwar fest, dass der Nutzer über seine European Digital Identity Wallet die volle Kontrolle behalten soll. Über die Nutzung der Wallet soll der Herausgeber keine Informationen sammeln, die nicht notwendig für die Wallet-Dienstleistungen sind. Datenschutzexperte und Informatiker Lukasz Olejnik rät jedoch wegen dieser sensiblen Nutzungsdaten in seiner Stellungnahme, die Rechte der Nutzer weiter zu stärken und zusätzlich vorzuschreiben, dass nicht mehr benötigte, aber bereits gesammelte Daten über die Wallet-Nutzung gelöscht werden sollen. Mehr als zwei Jahre sollten sie keinesfalls festgehalten werden, so Olejnik, wünschenswert wäre eine viel kürzere Frist von nur einem Monat.
Lohninger kritisiert, dass nicht schon von vornherein ein technischer Ansatz vorgeschrieben werde, um die Nutzungsdaten beim Wallet-Herausgeber zu minimieren. Er optiert für eine technische Infrastruktur, die eine Informationssammlung beim Herausgeber weitgehend unterbinde. Die entsprechende Passage müsse schon deswegen geändert werden, weil das Vertrauen der potentiellen Nutzer in die ID-Wallet durch technische Maßnahmen zum Datenschutz viel deutlicher gestärkt werden müsse. Denn ohne Vertrauen seitens der Nutzer drohe das ganze Vorhaben zu scheitern.
Damit die ID-Wallet breite Akzeptanz findet, muss es neben dem Vertrauensvorschuss auch möglichst viele Angebote geben, die von Menschen genutzt werden könnten. Sonst endet der Vorschlag vielleicht wie die deutsche eID im Personalausweis, die – selbst nachdem sie per Gesetz zwingend aktiviert ist – noch immer kaum Nutzer findet. Der Entwurf der Verordnung sieht daher eine Verpflichtung zur Akzeptanz der ID-Wallet bei Staat und Wirtschaft vor, versucht also durch eine vielfältige Angebotsseite die Nutzung anzuregen. Die sehr großen Plattformbetreiber sollen daher mitmachen müssen, aber auch eine ganze Reihe anderer Wirtschaftsbranchen, etwa Transport, Energie, Banken, Gesundheit, Post, Telekommunikation und weitere sollen verpflichtet werden.
Die IT-Sicherheit bei Smartphones
Ein in der Anhörung vielfach vorgebrachter Kritikpunkt ist das Fehlen vieler rechtlicher und technischer Details für das Design und die Nutzungsmöglichkeiten der Wallet: Das mache eine Risikoanalyse und eine sinnvolle Datenschutz-Folgenabschätzung im Sinne der Datenschutzgrundverordnung fast unmöglich, so Lohninger. Das betonte auch der Europäische Datenschutzbeauftragte Wiewiórowski, der anmerkte, eine Prüfung, ob alle Standards der DSGVO eingehalten werden, sei aktuell nicht möglich.
Schwierig sei zudem, dass die IT-Sicherheit der ID-Wallet als App von der IT-Sicherheit von Smartphones abhänge, sagte Lohninger. Das stelle viele Menschen vor Probleme, etwa wenn sie nicht die finanziellen Mittel hätten, um neuere Smartphones mit regelmäßigen Updates zu nutzen. Schon deswegen müsse in die Vorschläge zur ID-Wallet eine Anti-Diskriminierungsklausel hinein, damit nicht Menschen mit weniger Geld nach der Einführung der Digital-Brieftasche auch noch Aufpreise zahlen müssen, wenn sie diese digitale Identität nicht nutzen können. In seinem Heimatland Österreich sei das bereits zu beobachten.
Millionen Browser-Nutzer gefährdet
Besonders in der Kritik von Seiten vieler IT-Experten steht auch der geplante Artikel 45 der Verordnung. Darin geht es um Zertifikate in Browsern. Solche Zertifikate werden von Certificate Authorities (CAs) verwaltet. Sie haben eine Funktion wie ein Notar, der beglaubigt, dass Zertifikate echt sind. Der Kommissionsvorschlag würde eine staatliche Zertifikatsinfrastruktur über solche CAs in Browsern verpflichtend vorschreiben. Lukasz Olejnik hält das Vorhaben in seiner Stellungnahme für hochgefährlich und schlägt vor, den Artikel 45 wegen seiner potentiellen Auswirkungen auf die IT-Sicherheit und auf Grundrechte komplett zu streichen oder aber mindestens statt einer Verpflichtung eine Opt-In-Lösung aufzunehmen.
Die Electronic Frontier Foundation fand in einer im Dezember veröffentlichten Stellungnahme deutliche Worte, was die Folgen angeht, würde der Vorschlag so in Kraft treten: „Die Sicherheit von HTTPS im Browser könnte um vieles schlimmer werden.“ Millionen Browser-Nutzer wären außerdem betroffen. Auch Lohninger kritisiert, dass der Vorschlag für die IT-Sicherheit von Browsern gefährlich wäre und verheerende Konsequenzen („devastating consequences“) drohen würden. Er appellierte bei der Anhörung an die EU-Parlamentarier: „Please don’t break the web!“
Wegen massiver Verstöße gegen die Datenschutzgrundverordnung muss die niederländische Regierung ein Bußgeld von 2,75 Millionen Euro zahlen. Im Rahmen der sogenannten Toeslagenaffaire (deutsch: Kindergeldaffäre) hat die Steuerbehörde jahrelang in diskriminierender und unrechtmäßiger Weise Informationen über die Nationalität von Menschen genutzt, teilte die nationale Datenschutzbehörde im Dezember mit. Die Regierung räumte die Fehler inzwischen ein.
Die Aufsichtsbehörde reagiert mit dem Bußgeld auf einen Skandal, der die Niederlande bis heute tief erschüttert. In den 2010er Jahren forderte die nationale Steuerbehörde Belastingdienst von zehntausenden Eltern fälschlicherweise Rückzahlungen des Kindergeldes. Bereits kleine Formfehler beim Ausfüllen von Formularen führten zu horrenden Forderungen, eine vermeintlich falsche Nationalität konnte jahrelang zu stigmatisierenden Betrugsermittlungen führen. Viele von staatlicher Unterstützung abhängige Familien wurden dadurch zu Unrecht in den Ruin getrieben.
Das Vorgehen der Behörde hatte dabei erwiesenermaßen eine rassistische Prägung. Wie die Datenschutzaufsicht in ihrer Pressemitteilung aufzählt, habe der Belastingdienst Daten über die Nationalität von Kindergeldbewerber:innen als Indikator für verschiedene Zwecke genutzt. So sei etwa die Information, ob jemand eine doppelte Staatsbürgerschaft hat, in die Entscheidung über die Vergabe der Unterstützungsleistung eingeflossen, obwohl die Steuerbehörde diese Daten über mehr als 1,4 Millionen Menschen längst hätte löschen müssen.
Bei der Erkennung und Bekämpfung von Betrugsfällen seien Informationen über die Staatsangehörigkeit der Betroffenen ebenfalls als Verdachtsmarker genutzt worden. Auch in einem automatisierten System zur Risikoprüfung von Antragsteller:innen sei eine nicht-niederländische Nationalität als Risikofaktor gewertet worden. Wer eine nicht ausschließlich niederländische Staatsbürgerschaft hatte, war der Steuerbehörde per se verdächtig.
Opfer mussten für Aufklärung kämpfen
„Die Bevölkerung hat keine Wahl, als ihrer Regierung die Verarbeitung ihrer persönlichen Daten zu erlauben“, erklärte der niederländische Datenschutzbeauftragte Aleid Wolfsen in einem Statement. Deshalb sei es unabdingbar, dass alle absolutes Vertrauen haben können, dass diese Verarbeitung vernünftig abläuft. „Dass die Regierung keine Daten über Individuen behält und nutzt, die eigentlich nicht notwendig sind. Und dass es niemals eine Form von Diskriminierung gibt, wenn Menschen in Kontakt mit Behörden treten“, ergänzte Wolfsen.
Eine Sprecherin des Finanzministeriums bestätigte netzpolitik.org, dass ihr Haus das Bußgeld akzeptiere und Maßnahmen eingeleitet habe, um die diskriminierende Datenverarbeitung zu unterbinden. Unter anderem habe der Belastingdienst die Datenbank mit Informationen über die doppelte Staatsbürgerschaft gelöscht.
Die niederländische Regierung hatte ihr Fehlverhalten erst nach zahlreichen Vertuschungsversuchen eingestanden. Opfer des Skandals mussten jahrlang für Aufklärung und Anerkennung kämpfen. Ihnen wurde inzwischen die Rückzahlung der Mittel sowie eine Entschädigung in Höhe von je 30.000 Euro zugesagt.
Nachdem ein parlamentarischer Untersuchungsausschuss Ende 2020 die systematische Diskriminierung und massives Unrecht festgestellt hatte, trat Anfang 2021 das gesamte Kabinett unter Premierminister Mark Rutte zurück. Nachhaltig geschadet hat der Skandal dem Langzeit-Premier aber offenbar nicht: Bei den Wahlen im März wurde Ruttes rechtsliberale Partei VVD erneut stärkste Kraft, erst im Dezember einigte sie sich mit den drei anderen Regierungsparteien auf eine Fortführung ihrer Koalition unter Ruttes Führung.
Datendiskriminierung: „Wenn es schiefgeht, dann richtig“
Weltweit sorgen immer wieder Fälle für Aufsehen, bei denen Verwaltungen sensible Daten für die automatisierte Bewertung von Bürger:innen nutzen und dabei massive Fehler machen. In Australien etwa versendete eine Algorithmus fälschlicherweise Nachzahlungsforderungen an Empfänger:innen staatlicher Mittel und stürzte damit hunderttausende Menschen in die Krise. Österreich streitet seit Jahren über ein System, das die Chancen von Arbeitssuchenden auf dem Jobmarkt vorhersagen soll und dabei systematisch Frauen und alte Menschen benachteiligt.
Das Bußgeld in den Niederlanden ist der wohl erste Fall, bei dem eine Regierung eine Strafe für die datenbasierte Diskriminierung von Bürger:innen zahlen muss. Der Datenschutzbeauftragte Aleid Wolfsen hebt deshalb die grundsätzliche Bedeutung des Falles hervor. „In einer Welt, in der die Digitalisierung rasant voranschreitet, wird es immer wichtiger, die persönlichen Daten von Individuen zu schützen, um andere Grundrechte wie die auf Sicherheit, Eigentum und Gesundheit zu wahren.“
Der Fall zeige exemplarisch, warum dies so wichtig ist. „Die unrechtmäßige Datenverarbeitung durch einen Algorithmus führte zu einer Verletzung des Rechts auf Gleichbehandlung und Nicht-Diskriminierung“, so Wolfsen weiter. Digitale Anträge seien inzwischen unersetzlich und würden es ermöglichen, große Informationsmengen auf praktische Weise zu verarbeiten und zu kombinieren. „Aber wenn das schiefgeht, dann geht es richtig schief.“

















.jpg){kind=link}