Tails 7.8.1: Notfall-Release behebt Sicherheitslücken
Cloud and AI Development Act: EU-Kommission greift bei US-Cloud-Anbietern kaum durch
Die EU-Kommission hat ein Gesetz vorgestellt, mit dem sich die Mitgliedstaaten in Sachen Cloud und KI-Entwicklung von US-amerikanischen Anbietern unabhängiger machen sollen. Doch das Gesetz bleibt zurückhaltend und lässt vieles offen, kritisieren Fachleute.

„Über Geld spricht man nicht“ heißt es hierzulande gerne. Außer mit dem Finanzamt natürlich. In der Steuerverwaltung landen Informationen über Einkünfte, in der Sozialverwaltung landen Informationen über Phasen von Arbeitslosigkeit oder Wohngeld-Auszahlungen, in der Gesundheitsverwaltung landen Informationen über Krankheitsverläufe. Sensible Informationen, die viel über unser Leben verraten.
Und was macht die öffentliche Verwaltung damit? Sie schiebt die Daten zunehmend in die Cloud. Die gehört meistens Microsoft, Google, Amazon oder Oracle. Ob direkt oder über einen Subunternehmer – Verwaltungen greifen meist auf Dienste US-amerikanischer Cloud-Anbieter zurück.
Sind die Daten in einer solchen Public Cloud sicher? Und sollten Behörden in Sachen digitale öffentliche Infrastruktur auf US-Big-Tech setzen? Diese Fragen sind drängender geworden, seitdem bekannt wurde, welchen Einfluss US-Präsident Donald Trump hier ausübt und ausüben kann.
Die „geopolitische Lage“ heißt Trump
Diese „geopolitische Lage“ sei dringlich, so die Vizepräsidentin und EU-Kommissarin Henna Virkkunen bei der gestrigen Pressekonferenz zum neuen Tech Sovereignty Package. Es umfasst den Chips Act 2.0, die Open-Source-Strategie der EU und den Fahrplan für Digitalisierung und KI im Energiesektor.
Welchen Zugriff die US-Regierung künftig auf europäische öffentliche Informationen haben kann, will die Kommission mithilfe des Cloud and AI Development Acts (CADA) regulieren; das vierte Element im Packet. Doch gerade CADA scheint ein sehr zaghaftes Instrument der EU für mehr Unabhängigkeit von US-Big-Tech zu werden. Denn für einen großen Teil staatlicher Daten schließt die Kommission US-Cloud-Anbieter nicht vom europäischen Markt aus.
Nach ihrer Rechnung könnten gut 99 Prozent, mindestens aber 70 Prozent, staatlicher Daten der EU-Mitgliedsländer auf Clouds von US-Anbietern landen. Diese Zahlen beruhen auf einer Schätzung der Kommission zur Risikobewertung staatlicher Daten. EU-Mitgliedstaaten sollen nach einem vorgegebenen Stufensystem die Risiken bei der Beschaffung von Cloud-Diensten prüfen.
Zugriff auf Daten durch US-Regierung
Auf der anderen Seite des Atlantiks stehen dem Pakt Gesetze wie der Foreign Intelligence Surveillance Act (FISA), der Patriot Act und der CLOUD Act (Clarifying Lawful Overseas Use of Data Act) gegenüber. Laut CLOUD Act sind Tech-Unternehmen mit Sitz in den USA wie Microsoft oder Google dazu verpflichtet, unter bestimmten Voraussetzungen Daten gegenüber US-Behörden offenzulegen.
Dazu zählen auch Daten aus der EU. Das ist unabhängig davon, ob die Daten eines US-Unternehmens auf einem Rechenzentrum innerhalb der EU gespeichert sind, so ein juristisches Gutachten der Universität Köln im Auftrag des Bundesinnenministeriums. Bestätigt hat das aber auch der Chefjustiziar von Microsoft Frankreich, Anton Carniaux. Vor gut einem Jahr erklärte er dem französischen Senat: Wenn französische Behörden Microsoft nutzen, kann die US-Regierung diese Daten einsehen. Dafür müssen die Behörden nicht einmal ausdrücklich zugestimmt haben.
Trump kann sogar öffentliche Angestellte und Beamt:innen daran hindern, ihrer Arbeit nachzugehen. Das zeigen die Fälle von Richter:innen und einem Chefankläger am Internationalen Strafgerichtshof. Trump veranlasste, dass sie Dienste von Microsoft, Paypal und Co. nicht mehr nutzen können; auch auf ihre Accounts und darin enthaltene Daten können sie nicht mehr zugreifen.
Womit hält die EU dagegen?
Anhand von vier Sicherheitsstufen, den sogenannten „Union Assurance Levels“, sollen EU-Mitgliedstaaten nun die Cloud-Dienste auf den Prüfstand stellen, die sie nutzen: Welches Risiko wäre gegeben, wenn Daten an Nicht-EU-Staaten abfließen? Oder wenn ein Dienst ausfallen würde? Für diese Risikobewertung sollen die Länder ein Jahr Zeit haben, dann müssen sie ihre Ergebnisse veröffentlichen.
Demnach müssen Cloud-Anbieter für ihre Dienste je nach Stufe bestimmte Kriterien erfüllen. Stufe 1 benötigt ein niedriges Maß an Souveränität, Stufe 4 ein hohes. Bei Daten, die weniger sensibel sind, reiche die Sicherheitsstufe 1 aus. Demnach müssten Behörden lediglich sicherstellen, diese Daten in europäischen Rechenzentren zu speichern statt in beispielsweise US-amerikanischen. Öffentliche Auftraggeber in den EU-Mitgliedstaaten sollen nur Cloud-Dienste beschaffen, die mindestens Stufe 1 erfüllen. Hier ändert sich für die großen Cloud-Anbieter aus den USA wie Amazon und Google nichts. Denn sie haben die dazu erforderlichen Niederlassungen in der EU und betreiben hier bereits eigene Rechenzentren.
Auch mit der zweiten Sicherheitsstufe würde sich für sie nichts ändern, das erklärte ein hochrangiger EU-Beamter. Die Kommission hat dabei das Risiko eines Kill Switch im Blick. Damit ist gemeint, dass Betreiber aus der Ferne das IT-System abschalten könnten. Der jeweilige Cloud-Anbieter muss bei Stufe 2 ausschließen, dass Nicht-EU-Länder wie die USA oder China den Kill Switch umlegen könnten.
Cloud-Anbieter aus den USA ausschließen?
Stufe 3 soll erfordern, dass sich Cloud-Anbieter innerhalb der EU befinden und von dort aus kontrolliert werden. Daneben sollen sie Mitarbeitende mit europäischer Staatsangehörigkeit beschäftigen. Einflussnahme durch Drittstaaten soll damit reduziert werden. Virkkunen erklärte auf der Pressekonferenz, dass es US-Cloud-Anbieter schwer haben würden, Stufe 3 zu erreichen.
Doch es gibt ein Schlupfloch: Nach Artikel 18 hat die Kommission die Möglichkeit „von den Anforderungen auf Stufe 3 abzuweichen und Drittstaaten für Cloud-Anbieter anzuerkennen“, so Dennis-Kenji Kipker, Research Director und Gründer des Frankfurter Cyberintelligence Institute, gegenüber netzpolitik.org. Dazu dienen sogenannte Angemessenheitsbeschlüsse im Gesetz. Solche Beschlüsse beim Thema Datenschutz haben in der Vergangenheit gezeigt, dass die Kommission die USA trotz erheblicher Bedenken als vertrauenswürdigen Partner ansieht.
Die höchste Stufe soll nicht nur besonders für sicherheitssensible Bereiche gelten, sondern biete laut Kommission auch maximale Souveränität: EU-Länder sollen ihren gesamten Technologie-Stack von der Hardware bis zur Software vollständig kontrollieren. Das würde Nicht-EU-Anbieter ausschließen. Demnach dürften Cloud-Anbieter in dieser Stufe keiner Einflussnahme aus einem Drittland unterliegen.
Mitgliedstaaten entscheiden
Es bleibe „den Mitgliedstaaten vorbehalten“, wie sie bewerten, was „souveränitäts- und sicherheitskritisch“ ist. Die Kommission gibt also nicht vor, wie die EU-Länder das Stufensystem umsetzen sollen. Sie empfiehlt etwa die Bereiche Justiz, Polizei und Grenzschutz der Stufe 2 zuzuordnen. Das kritisiert die Grünenpolitikerin Alexandra Geese. „Wer akzeptiert, dass eine außereuropäische Regierung im Ernstfall Einfluss auf den Betrieb kritischer digitaler Infrastrukturen von Justiz, Polizei, nationale Sicherheit und Grenzschutz nehmen oder deren Verfügbarkeit gefährden kann, schafft institutionalisierte Abhängigkeit.“
Der Stufe 4 ordnet die Kommission den Bereich Verteidigung zu. Das würde nur etwa ein Prozent staatlicher Daten betreffen. Der Großteil von 70 Prozent sei weniger schutzbedürftig und falle damit unter Stufe 1, während 20 Prozent unter Stufe 2 und neun Prozent unter Stufe 3 fielen.
Inwieweit EU-Länder jedoch US-Cloud-Anbieter meiden und wie „das Ergebnis der Bewertung und Einordnung des Sicherheitsniveaus“ ausfällt, hänge wesentlich von ihrem „Risiko-Sicherheitskontext“ ab, so Kipker. Die Kommission spricht hier kein Vergabeverbot aus. Die Länder entschieden also selbst, ob „in einem besonders sensiblen Anwendungsfall die Wahl eines hohen Sicherheitsniveaus einen außereuropäischen Anbieter faktisch ausschließt“.
Die Kommission gibt auch nicht vor, wie die EU-Länder ihre Behörden von einem Cloud-Anbieter wie Amazon oder Microsoft zu einem europäischen Anbieter migrieren. Immerhin hätte CADA nach Inkrafttreten „unmittelbare Geltung und Anwendungsvorrang, und die Kommission könnte Verstöße über das Vertragsverletzungsverfahren nach AEUV durchsetzen“, erklärt Kipker.
Das Gesetzespaket geht nun an das europäische Parlament und die Mitgliedstaaten. Gerade von letzteren hängt ab, ob sich die Cloud-Landschaft für die Behördenarbeit in der EU tatsächlich verändert.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Ubuntu is adding AI-powered voice input to all text fields
 Ever wished you could talk in to a text field rather than type? Ubuntu 26.10 hears you – quite literally. Canonical’s VP of Engineer Jon Seager, at the Ubuntu Summit, said the distro will soon lets users “press a button and talk into any field that you could previously type in”. A small, on-device AI language parsing model like Whisper will power the feature. It’s part of a wider push to integrate AI features in Ubuntu this year, with founder Mark Shuttleworth aiming to position Ubuntu as the ‘OS for agentic AI’. AI features in Ubuntu will be shipped as […]
Ever wished you could talk in to a text field rather than type? Ubuntu 26.10 hears you – quite literally. Canonical’s VP of Engineer Jon Seager, at the Ubuntu Summit, said the distro will soon lets users “press a button and talk into any field that you could previously type in”. A small, on-device AI language parsing model like Whisper will power the feature. It’s part of a wider push to integrate AI features in Ubuntu this year, with founder Mark Shuttleworth aiming to position Ubuntu as the ‘OS for agentic AI’. AI features in Ubuntu will be shipped as […]
You're reading Ubuntu is adding AI-powered voice input to all text fields, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
EU-Rat und Parlament einigen sich: Ein Abschieberegime, von dem Rechtsextreme geträumt haben
Europaparlament und Regierungen verschärfen die Abschieberegeln. Auch Abschiebezentren in Drittstaaten und Razzien nach dem Vorbild der US-Abschiebe-Miliz ICE werden möglich. Ob die neuen Regelungen tatsächlich mehr und schnellere Abschiebungen erreichen werden, bleibt indes fraglich.

Vertreter*innen des Europaparlaments und der EU-Länder haben sich am Montagabend auf eine neue Rückführungsverordnung geeinigt. Das Ziel: mehr und effizientere Abschiebungen von Drittstaatsangehörigen ohne regulären Aufenthalt.
Einen ersten Entwurf für das Gesetz, das auch als „Abschiebeverordnung“ bekannt ist, hat die EU-Kommission bereits im vergangenen Jahr vorgestellt. Sie soll die Reform des Gemeinsamen Europäischen Asylsystems (GEAS) ergänzen, die in der gesamten EU am 12. Juni wirksam wird.
Trotz massiver Kritik von Jurist*innen und Menschenrechtsorganisationen halten die EU-Institutionen dabei an ihrem harten Kurs fest. So sollen Menschen künftig in Abschiebezentren außerhalb des EU-Territoriums gebracht werden können, auch ohne eine vorherige Verbindung zu dem Land. Menschen ohne Papiere sollen außerdem länger inhaftiert, mit langen Einreiseverboten belegt und für fehlende Kooperation bestraft werden können. Auch sollen ihre Wohnungen leichter durchsucht werden können, sie sollen verstärkt digital überwacht und ihre Datenträger durchleuchtet und beschlagnahmt werden.
EU-Innen- und Migrationskommissar Magnus Brunner bezeichnete die Einigung als „einen wichtigen Schritt in der europäischen Migrationswende“. Sarah Chander von der Initiative „We Keep Us Safe“ sprach gegenüber netzpolitik.org hingegen von einem Gesetzestext, der es „rechtsextremistischen Fraktionen ermöglicht, ein von Überwachung geprägtes Abschieberegime ihrer Träume zu errichten“.
Abschiebezentren und verlängerte Abschiebehaft
Mit der Verordnung hat die EU den Weg für sogenannte „return hubs“ geebnet, in die Menschen abgeschoben werden sollen, deren Abschiebung bisher scheitert. Das kann an einer Vielzahl von Gründen liegen, beispielsweise wenn Menschen keinen Pass haben, das Herkunftsland die Wiedereinreise verweigert oder keine diplomatischen Beziehungen bestehen.
Solche Abschiebezentren sollen zum einen als Transitzentren dienen, um die „Weiterreise in das Herkunftsland oder ein anderes Drittland zu erleichtern“. Gleichzeitig schließt der Rat nicht aus, dass Abschiebezentren das endgültige Ziel darstellen könnten – also auf unbestimmte Zeit. Während unbegleitete Minderjährige von der Abschiebung in solche Zentren verschont bleiben, können Familien mit Kindern dort festgehalten werden. Das gilt als menschenrechtlich sehr umstritten.
Bundesinnenminister Alexander Dobrindt (CSU) hat angekündigt, gemeinsam mit anderen EU-Staaten – darunter Österreich, Dänemark und Griechenland – bis Ende des Jahres Deals zur Errichtung solcher Zentren mit Drittstaaten aushandeln zu wollen. Bis auf Uganda, das eine solche Vereinbarung mit den Niederlanden getroffen hat, gibt es bisher keine konkreten Beschlüsse. Im Gespräch sind Länder wie Ruanda, Libyen, Mauretanien, Usbekistan und Äthiopien.
Zusätzlich gibt die Verordnung grünes Licht, unbegleitete Kinder sowie Familien mit Kindern innerhalb der EU in Abschiebehaft zu nehmen. So hat Polen beispielsweise die Inhaftierung von unbegleiteten Kindern ab 15 Jahren bereits seit Anfang des Jahres durch nationales Recht erlaubt. Mit der Verordnung wird zudem die Dauer der Abschiebehaft auf 24 Monate ausgeweitet und kann um weitere sechs Monate verlängert werden, wenn sich die Zusammenarbeit mit dem betreffenden Drittland verbessert oder die Behörden der Ansicht sind, dass Fluchtgefahr besteht.
ICE-ähnliche Hausdurchsuchungen und elektronische Überwachung
Andere geplante Maßnahmen sind unter zivilgesellschaftlichen Organisationen nicht weniger umstritten. So übte Sarah Chander von der Initiative „We Keep Us Safe“ harte Kritik an den Plänen. Asyl und Legalisierung würden damit zu Tabus, Hausdurchsuchungen, invasive Datenerhebung und ‑weitergabe würden zur Norm. „Anstatt in Fürsorge und Schutz zu investieren, werden öffentliche Mittel dazu verwendet, internationale und EU-Rechtsstandards vollständig auszuhöhlen.“
Dazu gehört beispielsweise das Grundrecht auf die Unverletzlichkeit der Wohnung. So stattet die Verordnung die Mitgliedstaaten mit weitreichenden Befugnissen aus, private Wohnungen von Drittstaatsangehörigen ohne gültigen Aufenthalt und andere „relevanten Räumlichkeiten“ zu durchsuchen. Diese Regelung könne Menschenjagden auf Migrant*innen nach Vorbild der USA nach sich ziehen sowie ganze Communitys rassistischer Diskriminierung aussetzen, warnten zuletzt UN-Menschenrechtsexpert*innen sowie mehr als 100 zivilgesellschaftliche Organisationen.
„Auf der anderen Seite des Atlantiks sehen wir die Gewalt und Angst, die durch die brutale Einwanderungskontrolle der ICE verursacht wird“, sagte Silvia Carta von der Platform for International Cooperation on Undocumented Migrants (PICUM), eine der rund 100 kritischen Organisationen. „Europa sollte aus den Schäden dieses Modells lernen, anstatt eine eigene Version aufzubauen“, so Carta weiter.
Behörden dürfen laut den Plänen außerdem Handys, Computer sowie andere elektronische Geräte von Menschen ohne Papiere durchsuchen und beschlagnahmen – eine Praxis, die in einzelnen deutschen Bundesländern bereits verbreitet ist, wie Recherchen von netzpolitik.org gezeigt haben.
Weitere Zwangsmaßnahmen sehen vor, dass Menschen in Abschiebeverfahren sich nur an einem bestimmten Ort aufhalten, Ausgangssperren unterziehen oder regelmäßigen Meldepflichten nachkommen müssen. Als sogenannte Alternativen zur Inhaftierung können außerdem das Hinterlegen einer Geldsumme oder elektronische Überwachung auferlegt werden. Bei der letzteren handelt es sich laut Fachleuten nur vermeintlich um eine Alternative. Denn diese kommt aufgrund ihrer tief in die Privatsphäre eingreifenden Wirkung de facto einer Haft gleich und kann außerdem zusätzlich zur ausgedehnten Abschiebehaft verhängt werden. Denkbar sind dafür etwa eine elektronische Fußfessel oder GPS-Ortung.
Neue Europäische Rückkehrentscheidung vorerst ohne Wirkung
Das Kernstück der Verordnung ist die „Europäischen Rückkehrentscheidung“ (ERO). Diese enthält ein standardisiertes digitales Datenblatt mit Informationen zur Abschiebeentscheidung. Alle Mitgliedstaaten sollen dieses Datenblatt über das Schengener Informationssystem abrufen können.
Die gegenseitige Anerkennung von Abschiebeentscheidungen bleibt aber vorerst freiwillig: Ein EU-Land kann die erlassene Entscheidung eines anderen EU-Landes anerkennen und vollstrecken, muss es aber nicht. In diesem Aspekt waren sich das Parlament und die Mitgliedstaaten im Vorfeld uneinig. Während das Parlament auf eine verpflichtende Anerkennung ab 2027 pochte, war dieser Punkt unter den Mitgliedstaaten umstritten.
Laut der Pressemitteilung des Parlaments wird die EU-Kommission die gegenseitige Anerkennung innerhalb von zwei Jahren prüfen und dann gegebenenfalls die verpflichtende Anerkennung vorschlagen, laut den Mitgliedstaaten soll dies nach drei Jahren passieren. Der finale geeinigte Gesetzestext liegt noch nicht vor.
Mit ERO werden personenbezogene Daten von Menschen in Abschiebeverfahren für Tausende Polizeibeamt*innen in der gesamten EU zugänglich, warnen Menschenrechtsorganisationen. Das Schengener Informationssystem II, das größte Migration- und Polizeidaten-Austauschsystem der EU, sei für wiederholten Datenmissbrauch und die systematische Verweigerung der Datenschutzrechte bekannt. Es gibt dokumentierte Fälle, in denen Polizei- und Einwanderungsbehörden sich nicht an Vorschriften gehalten haben. Die Verordnung baut direkt auf dieser Architektur auf und verstärkt ihre Eingriffsintensität.
Menschen ohne Papiere „wie Straftäter behandelt“
Scharfe Kritik gab es auch von Abgeordneten im EU-Parlament. Mélissa Camara, Schattenberichterstatterin der Grünen für die Rückführungsverordnung, bezeichnete die erzielte Einigung als „beschämend“. Den Standpunkt des Parlaments hatte die konservative EVP-Fraktion unter der Führung des deutschen CSU-Politikers Manfred Weber mit rechtsaußen Parteien wie der AfD im März verhandelt und verabschiedet. „Dieser Text verankert fremdenfeindliche Ideen und Rhetorik auf Kosten der Grundrechte von Migranten, deren einziger Fehler darin bestand, mit dem falschen Pass geboren zu sein“, so Camara. „Grundrechte stehen an der Spitze der Normenhierarchie und dürfen nicht einfach mit Füßen getreten werden.“
Auch die innenpolitische Sprecherin der europäischen Sozialdemokrat*innen Birgit Sippel äußerte sich kritisch zur Verordnung. „Parlament und Mitgliedstaaten haben im Hau-Ruck-Verfahren eine Einigung gefunden und damit trotz sinkender Ankunftszahlen der Panikmache der Rechten in Europa nachgegeben“, sagte sie. „Alle Betroffenen werden de facto wie Straftäterinnen und Straftäter behandelt.“
Die neuen Abschieberegeln müssen vom EU-Parlament und den EU-Staaten noch formal abgesegnet werden. Die Verordnung tritt in Kraft, sobald sie im Amtsblatt der EU veröffentlicht wurde. Einige Bestimmungen, darunter solche zu den Abschiebezentren, gelten dann sofort. Andere Regelungen werden nach einer Übergangszeit von zwölf Monaten angewandt.
Ob die Verordnung tatsächlich zu höheren Abschiebezahlen führen wird, bleibt indes fraglich. Mehr als 250 Organisationen gehen davon aus, dass sie den gegenteiligen Effekt haben wird: Da Abschiebung zur Standardoption für Menschen ohne legalen Aufenthalt wird, werde die Verordnung die Zahl der ausreisepflichtigen Menschen eher künstlich in die Höhe treiben. Auch die von der Politik häufig bemühte Erzählung einer Vollzugslücke – etwa dass es einen massiven Rückstand an Abschiebungen gebe und nur jede fünfte Person, gegen die eine Ausreiseanordnung ergangen ist, tatsächlich abgeschoben werde – basiert auf falschen Zahlenspielen und statistischen Verzerrungen, kritisieren Wissenschaftler*innen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
IBM will 5 Milliarden Dollar in Open-Source-Sicherheit investieren
I Tried This Open Source ChatGPT Alternative on Linux, But Went Back to Ollama
I may hate AI slop but I am not a AI hater. I have found decent use of the AI tools and I try to include these tools in my workflow wherever it makes sense.
While mainstream LLMs like ChatGPT and Perplexity have decent free offering, they leach on the user data. "If you are not paying for the product, you are the product".
That's why I am loving the idea of exploring local AI and I have spend my fair share of time experimenting with LLMs that can be run on normal systems.
Recently, I discovered Jan AI. It is a polished, genuinely usable desktop app that runs entirely on my machine. In fact, I once tried replacing Ollama and llama cpp with Jan AI, but later changed my mind.
I'll explain why I switched back to Ollama in the later sections. First, let's learn about Jan AI.
What is Jan AI?
Jan is a free and open-source desktop application that lets you run various large language models directly on your own hardware. You can think of it as a self-hosted, offline-capable ChatGPT, except the model runs on your CPU or GPU, and no data ever leaves your machine.
The project is developed by the Jan.ai company, and the source code is available on GitHub under the AGPL-3.0 license. It's built on top of llama.cpp under the hood, which means it can run quantized GGUF models efficiently even without a dedicated GPU.
What I found impressive is that Jan's desktop application is built using the Tauri framework instead of Electron JS, which gives it a good performance boost and I think eats less RAM, too.
A quick catch, you still need plenty of RAM for running your local LLM.
The app supports Linux, macOS, and Windows. I used it on my Linux machine.
System requirements
Running a local LLM with Jan AI does require decent hardware. Here's what to realistically expect:
- 8 GB RAM minimum. It's enough for 7B parameter models at 4-bit quantization (Q4_K_M). You'll notice slowdowns with other applications open. 16 GB RAM is the sweet spot. It can comfortably run 7B models and lets you experiment with 13B models.
- GPU acceleration is optional but makes a big difference. Jan supports NVIDIA (via CUDA), AMD (via ROCm), and Intel Arc. If you don't have a compatible GPU, CPU-only mode works, but it's significantly slower.
- Disk space models range from around 4 GB (7B, Q4) to 8 GB+ (13B). Download only what you need.
Installing Jan AI on Linux
Jan offers multiple installation formats, including .deb and AppImage, but the AppImage is what I'd recommend for most Linux users. It's a single self-contained file that runs on virtually any distro without touching your system packages or requiring root privileges for the app itself. It requires no dependency hell. It's just made to work.
I am not going in the details but if you need help, refer to this guide to use AppImage on Linux.
When you run Jan AI for the first time, you should see an interface like this:
Downloading models and putting Jan to work
A freshly installed Jan is essentially an empty shell capable, but waiting. The first thing you need to do is grab a model. Think of it like the app is the frame and the model is the brain.
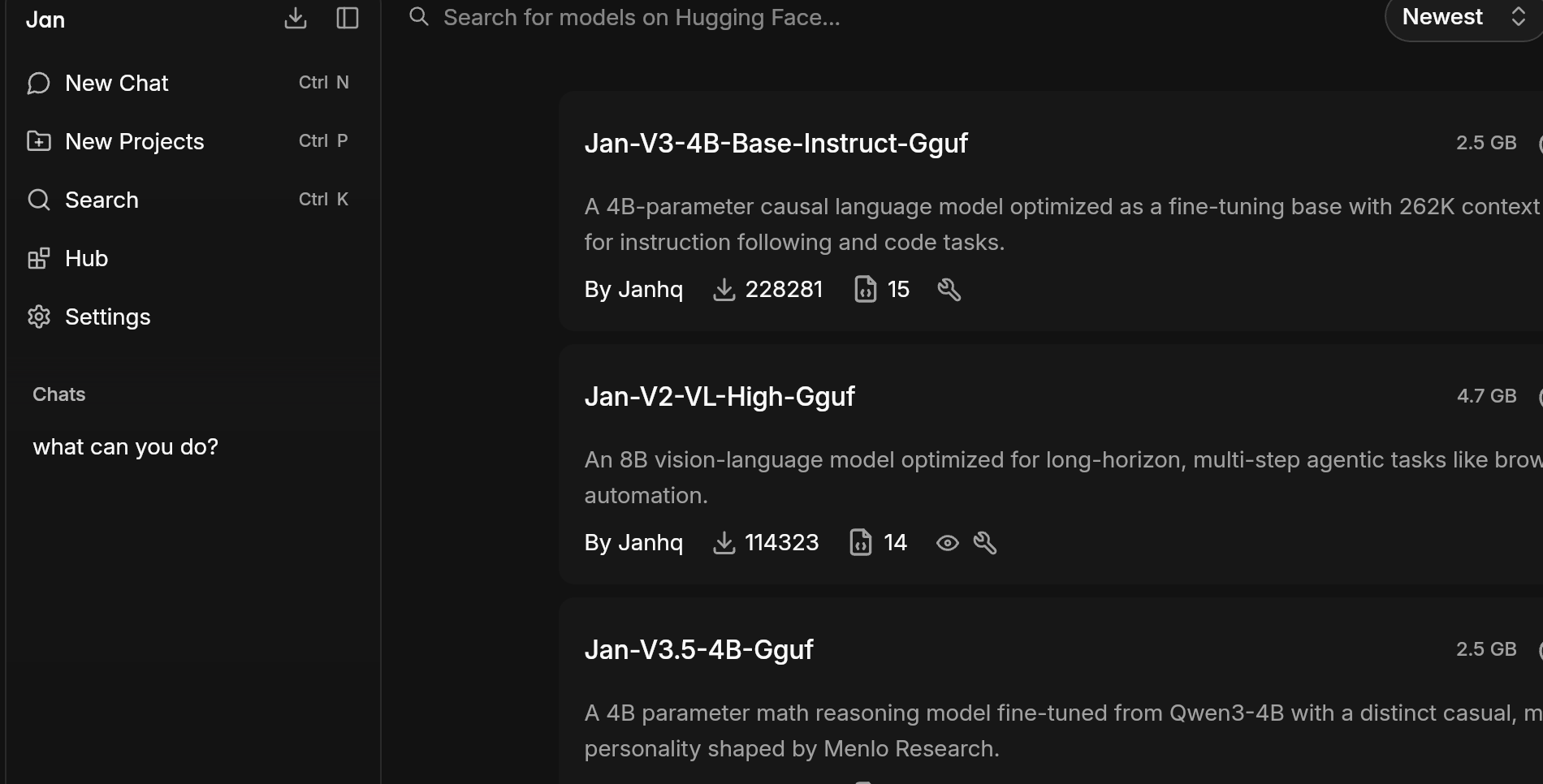
Finding your way to the model hub
Click the Hub in the left sidebar. This is Jan's built-in model library, a curated list of open-source models you can download with a single click.
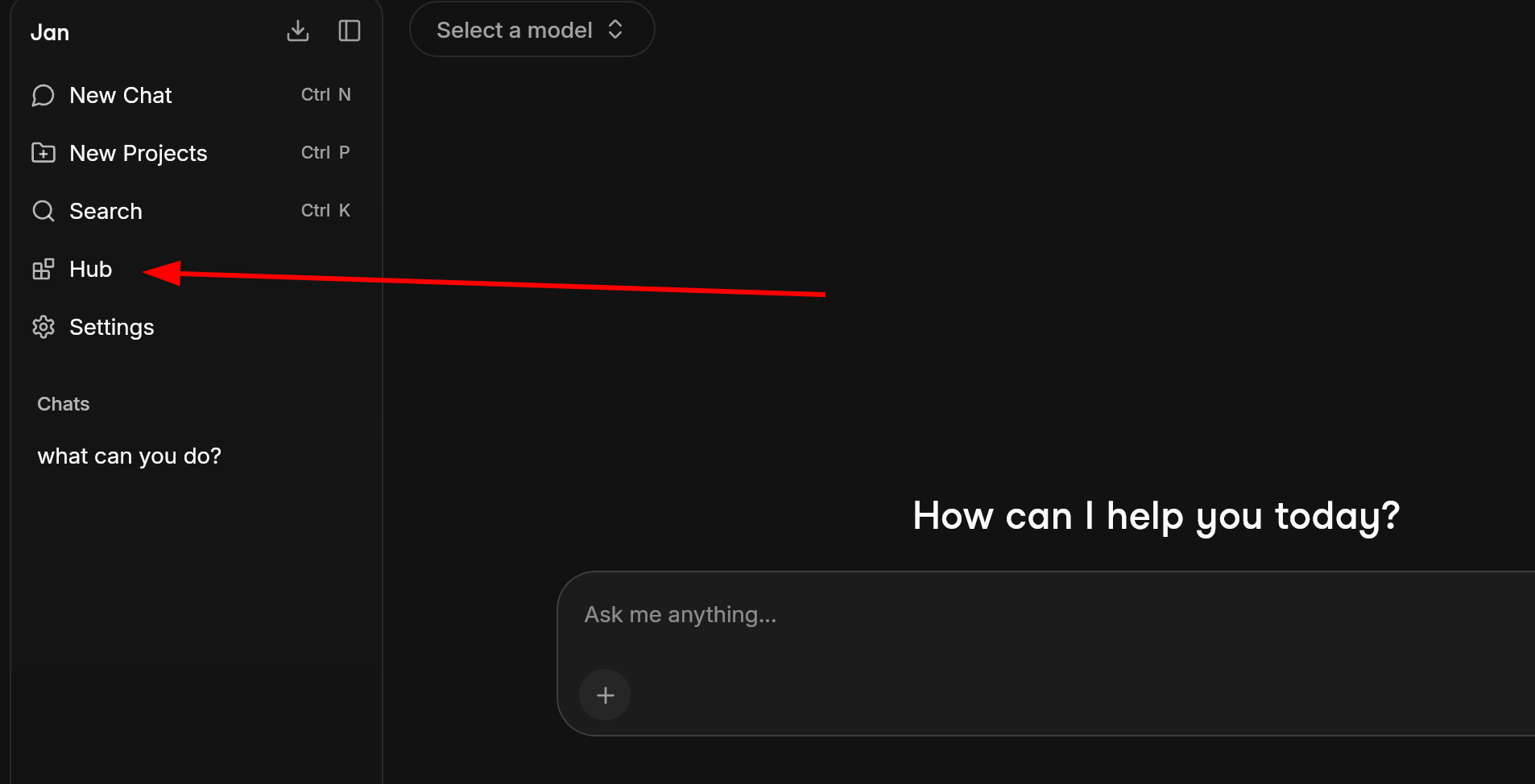
There are dozens of models with names full of numbers and letters like Q4_K_M or IQ3_XS.
Before I recommend which ones to pick, let me quickly demystify that alphabet soup because I spent an embarrassing amount of time confused by it when I first started.
What does Q4_K_M actually mean?
Every model name carries a quantization tag. Quantization is how a model's original full-precision weights get compressed to fit on consumer hardware. Here's a practical breakdown:
- Q4: 4-bit quantization. The most common choice. Roughly 4 GB for a 7B model. Fast, memory-efficient, and quality holds up well for everyday tasks.
- Q8: 8-bit quantization. Nearly full quality, but needs about twice the RAM. Worth trying if you have 32 GB or more.
- K_M: The specific compression method (K-quants, medium variant). Generally, the best balance of speed and quality within the Q4 family.
- XS (Extra Small): This is the most aggressive compression. It results in a file size that is slightly smaller than a standard Q4_K_S
Q4_K_M. If you have 32 GB+, try Q8_0 for noticeably sharper outputs.The 3 LLM models I tested
I am using an AMD laptop with an integrated GPU. I settled for CPU interference for local LLM models because enabling RoCm (Radeon Open Compute) is a hectic task, based on my research. It requires 25-30 GB of disk space.
For those of you who aren't familiar with what AMD ROCm is, it's the answer to NVIDIA's CUDA. Basically, when you run a local LLM, the heavy math, such as matrix multiplications across billions of parameters, can be offloaded to a GPU instead of the CPU.
RoCm lets software like Jan AI, PyTorch, or Llama.cpp talks to AMD Radeon GPUs to do that same heavy lifting. Without it, Jan falls back to CPU-only mode, which works but is significantly slower.
For this article, I settled on three models that cover a solid range of use cases. I asked the same question to each model - "What can you do"? Here's what I found:
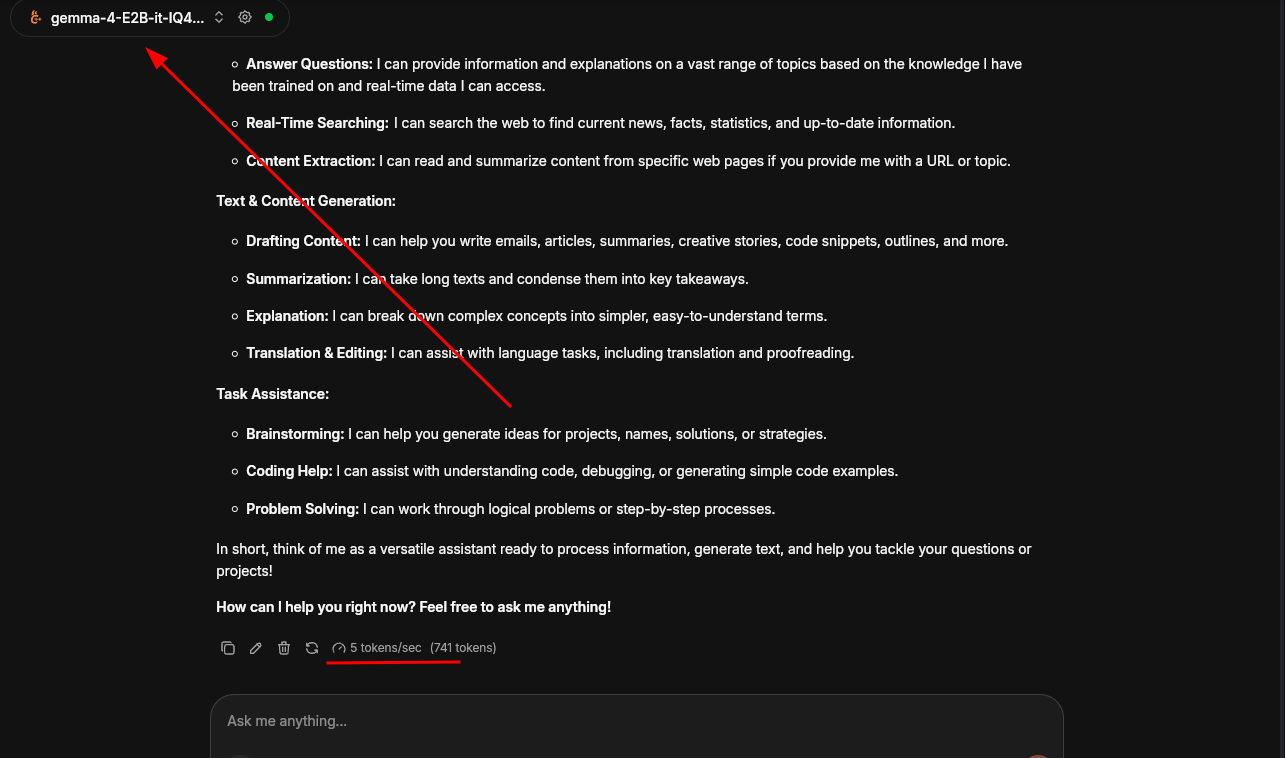
Gemma 4
I don't lie. The performance wasn't superb, only 5 tokens per second.
Gemma 3
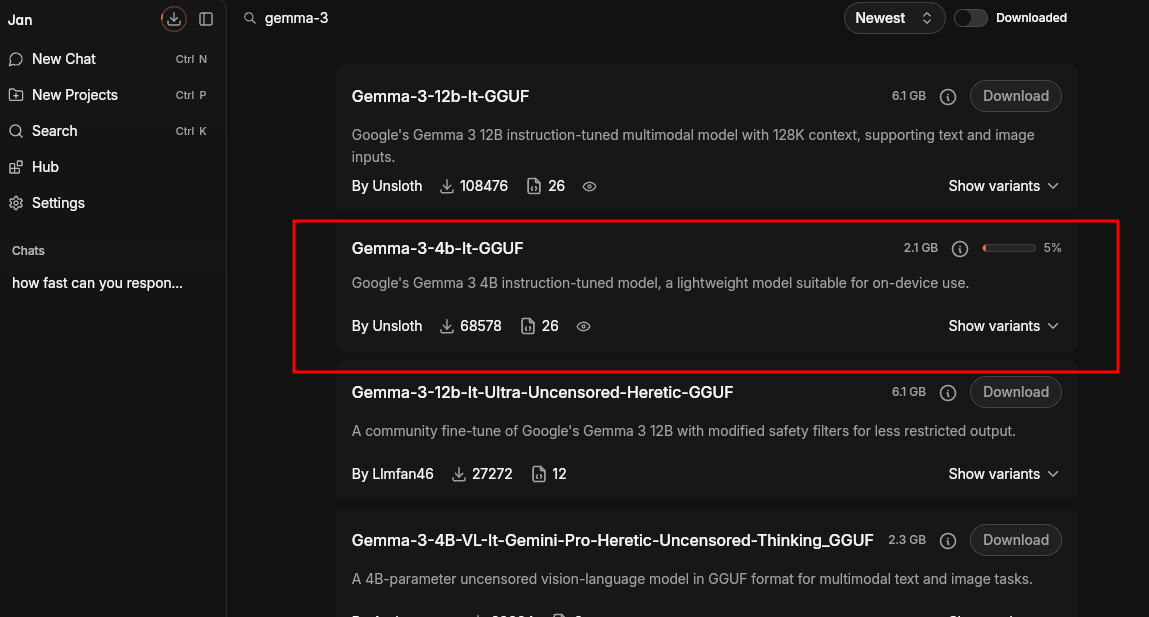
The performance was bad than the Gemma 4 2B model. It was only 3 tokens per second. I think you can use the Gemma 3 2B model variant to achieve comparable performance.
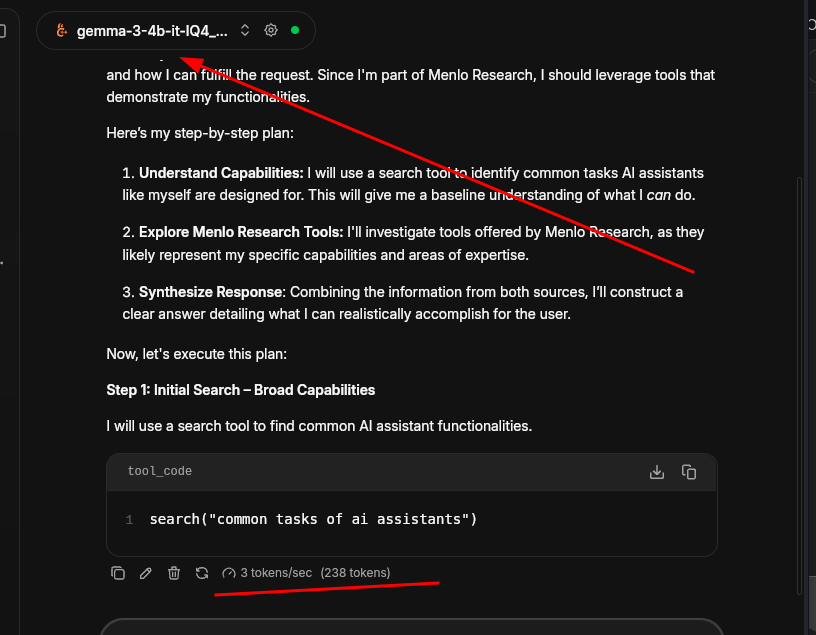
Jan
Yeah! Jan offers its own AI model. I used the Jan-v3-4b model to test. It comes with 262K context length. It can follow up instructions and do some light coding tasks.
Features I liked in Jan AI
Let's see a few features that I liked in this open source AI tool.
Unified Interface for Local and Cloud LLMs
Jan can act as a unified interface for local and cloud LLMs, instead of jumping from Claude to ChatGPT and then Gemini. You get to talk to your favorite LLMs within a single interface.
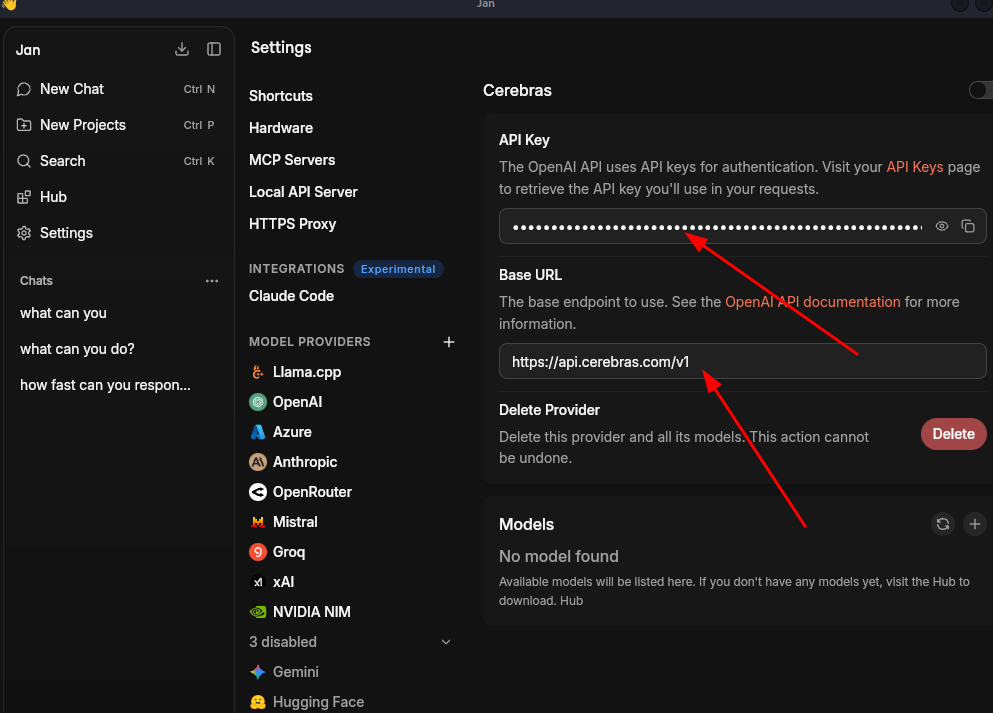
Though directly interacting with Cloud LLMs takes away your privacy, you can still use Jan AI as a unified interface to interact with any models on HuggingFace, Groq, Gemini, Qwen, Mistral, and Claude with the respective platform's API.
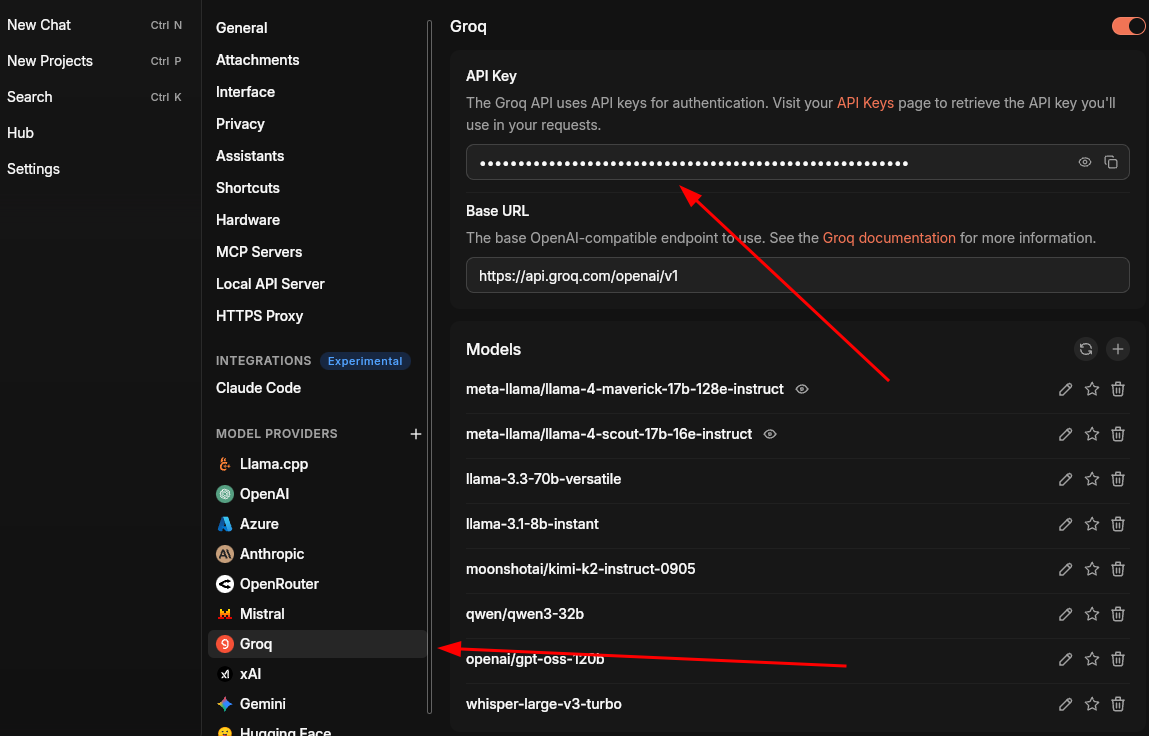
I'm especially in love with the Groq and Cerebras API. These platforms provide fast interference.
If your model provider is not in the list, you can still add OpenAI-compatible models to it.
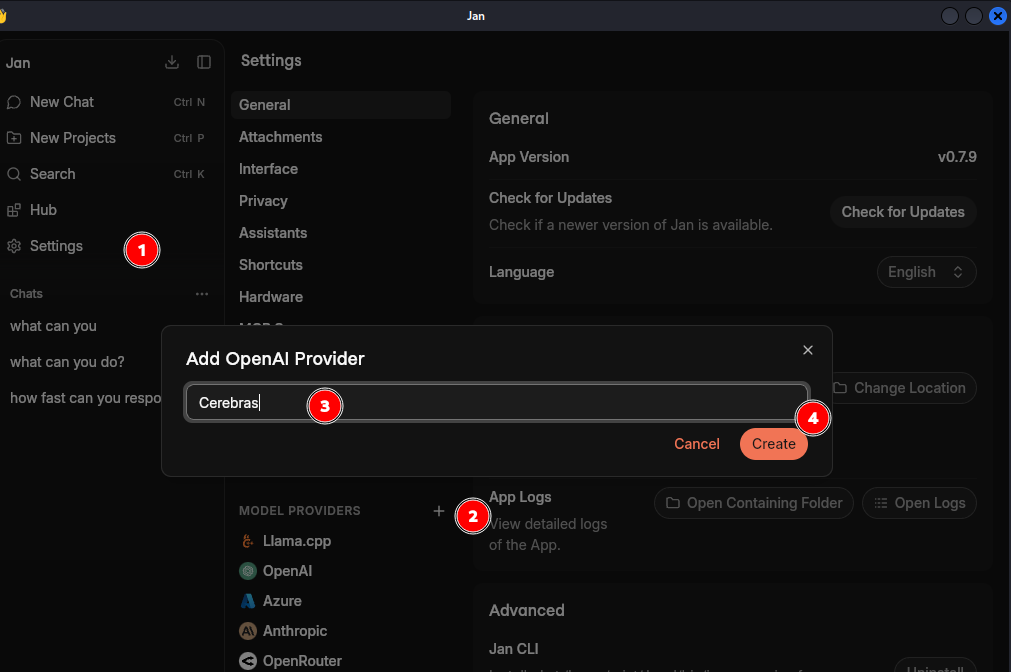
To add, click on the plus icon next to "MODEL PROVIDERS". It'll ask for a name. Enter the name and then set the BASE_URL and API Key provided by your LLM platform.
Keeps your chats organized
Jan offers the functionality to organize chats per project.
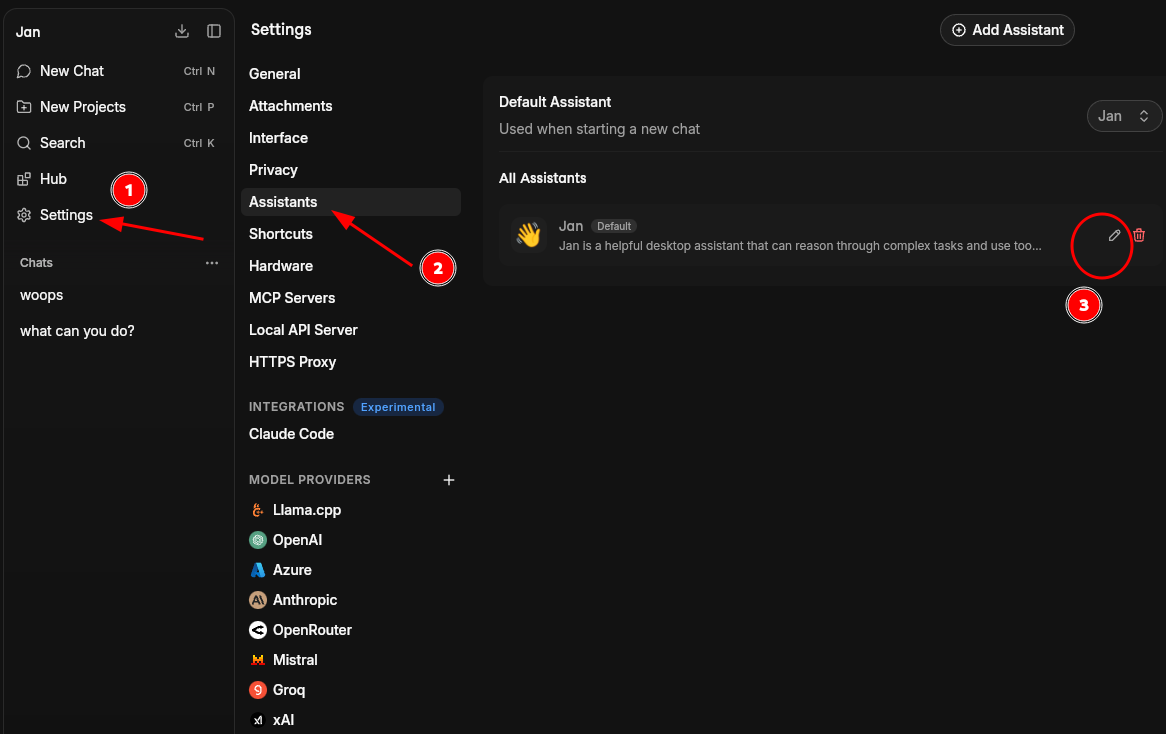
Tailor Jan for Custom Experience
You can edit the system instruction. It's kind of making LLM behave like a specific expert.
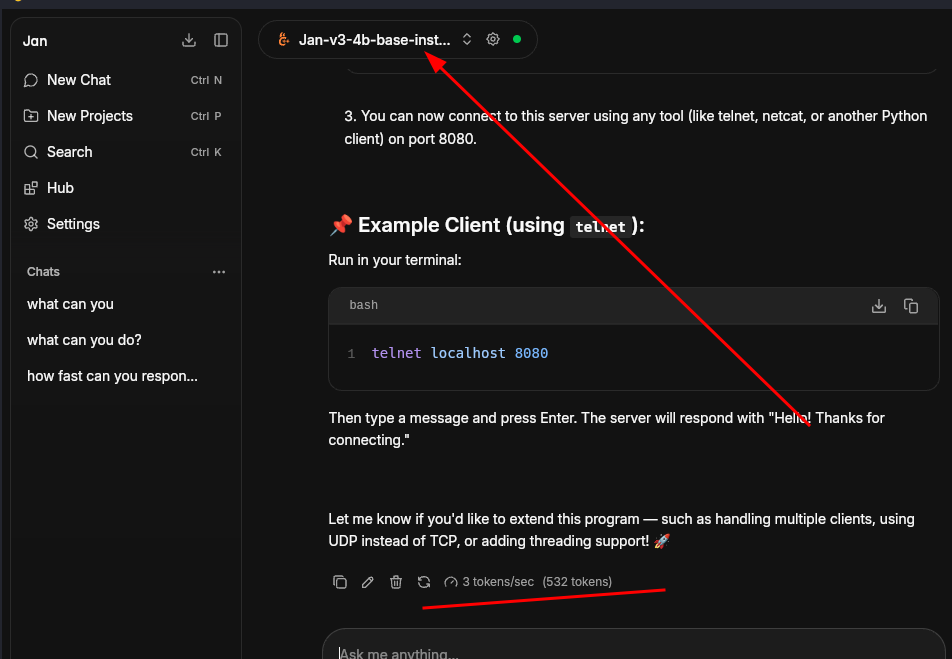
Local API Server
It comes with a local API server. You can start the server by going to Settings -> Local API Server.
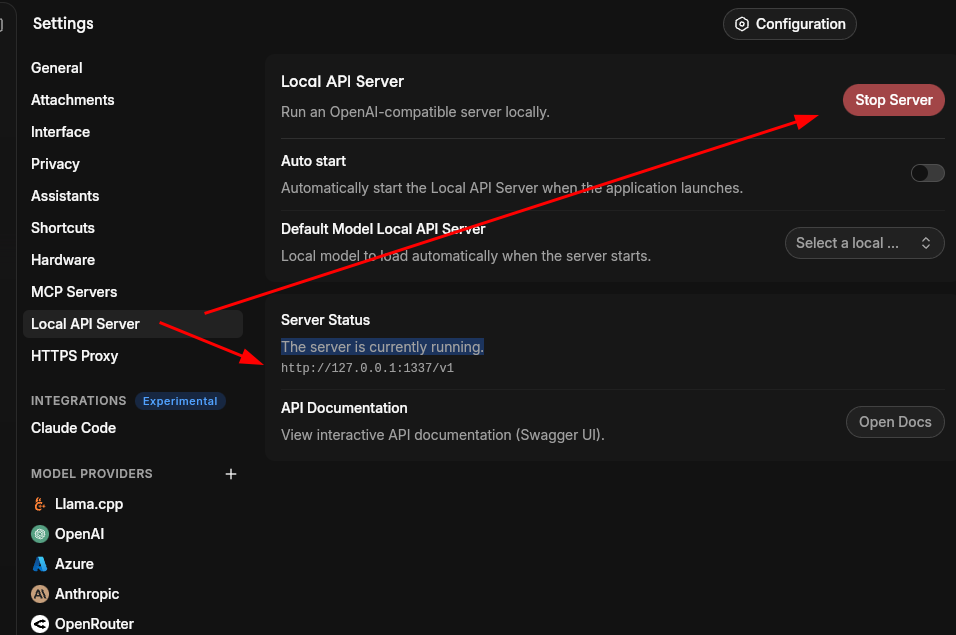
Use it as a tool to download AI models for Llama.cpp
Models downloaded with Jan AI application are completely compatible with Llama.cpp CLI. You can use Jan as a downloader tool and then run the downloaded AI model with llama-server a command.
Jan CLI
Jan offers a CLI interface to interact with as well.
My honest opinion on using Jan AI vs Ollama
Thanks to the developer involved in building the Jan AI app. It provides a nice GUI interface to interact with LLMs. On the contrary, I see some improvement scope for the application.
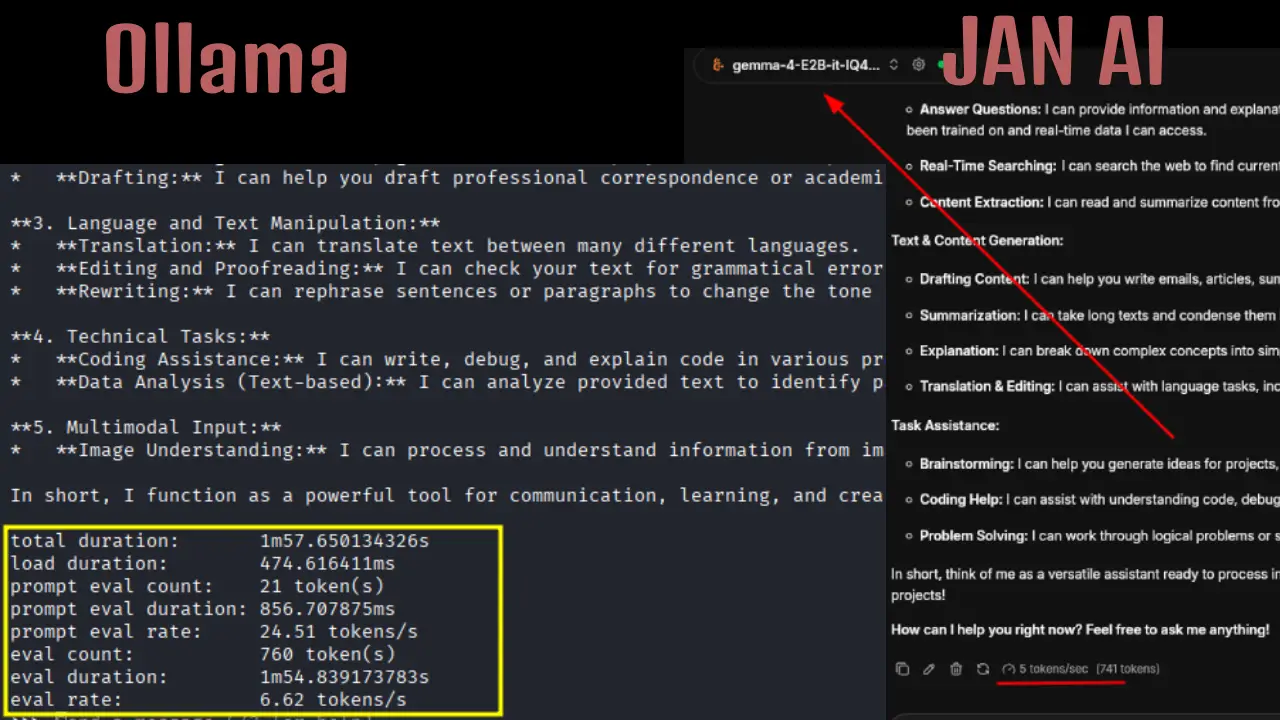
The major one is with the local LLM inference time. I tested the same model, and what I found was that Jan AI provided slow inference time as compared to Ollama on the same hardware. Ollama produced a response at a rate of 6.62 tokens/sec while Jan AI produced a response at around 5 tokens/sec.
On the second test, Ollama reported 7.35 tokens per second while Jan AI responded at 3 tokens per second. Also, I tried Llama.cpp for the same Gemma 5 E2B model with 3.97 tokens/sec.
The secondary issue is Jan application often freezes your system. I agree, running LLM models takes significant RAM memory, but there are a couple of attempts I faced where giving a prompt with the Gemma 4 E2B model freezes my system. I haven't faced any similar issue with Ollama. That's why I kept Ollama and Llama.cpp for my local AI model inference.
Who is Jan AI actually for?
After spending time with it, I'd say Jan AI fits a few kinds of people particularly well. One thing I need to justify here, although in my tests, Jan struggled to give me more than 5 tokens per second in CPU mode, running it on a system with modern GPUs like Radeon GPU, Intel Arc, Nvidia 4050, you may get to see a huge boost in performance, especially with tokens per second. You could achieve around 13-15 tokens per second.
Privacy-conscious users who want AI assistance without feeding their conversations to a corporation. Lawyers, journalists, healthcare workers, and anyone handling sensitive information fall into this category.
Developers who want a local AI backend for their tools. The OpenAI-compatible API makes it drop-in compatible with a surprising number of existing integrations.
Linux enthusiasts who simply prefer FOSS software and want to own their stack. The fact that it's AGPL-licensed and actively developed is a big plus.
People on a budget. It comes with no API costs or subscription. You run it on hardware you already own.
It's not for everyone. If you need GPT-4 level capability for complex reasoning tasks, you'll still feel the quality gap compared to frontier cloud models. But for writing assistance, summarization, brainstorming, and everyday tasks? A well-tuned 7B or 13B model gets the job done.
The bigger picture
Local AI is no longer a hobbyist experiment. The AI models like Gemma 4, Gemma 3, Granite, Jan AI model, and SmolLM2 have gotten small enough that a standard laptop can run something genuinely useful. Tools like Jan have made the setup approachable enough that you don't need to be a machine learning researcher to get started.
Jan AI won't replace cloud services for everyone. But for a growing number of Linux users who care about privacy, cost, and control, it's become a daily-use tool. I'd encourage you to try it. Download it, grab a 7B model, and see how far it gets you.

Flathub verschärft Regeln für KI-generierten Code
Flathub bans AI-coded apps – with some exceptions
![]() You’ll have to sift through fewer vibe-coded apps on Flathub in future, as the store has announced a policy change on software made using AI tools. Flathub, the de-facto place to find and install Flatpak applications, is banning the use of “AI” coded applications and automated submissions going forward. It’s not a blanket ban – mature projects with AI code are allowed A change to the store’s policy note says “applications containing AI-generated or AI-assisted code, documentation, or other content are not allowed”. A carve out will allow “mature, well-maintained projects” to include AI generated code and use AI tools […]
You’ll have to sift through fewer vibe-coded apps on Flathub in future, as the store has announced a policy change on software made using AI tools. Flathub, the de-facto place to find and install Flatpak applications, is banning the use of “AI” coded applications and automated submissions going forward. It’s not a blanket ban – mature projects with AI code are allowed A change to the store’s policy note says “applications containing AI-generated or AI-assisted code, documentation, or other content are not allowed”. A carve out will allow “mature, well-maintained projects” to include AI generated code and use AI tools […]
You're reading Flathub bans AI-coded apps – with some exceptions, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
KI-Klimaschwindel und Greenwashing: Big Tech erklärt das Problem zur Lösung
Die Beweise für positive Klimaauswirkungen durch sogenannte „KI“ sind schwach, während die Klimaschäden klar belegt sind. Ein Bericht von AlgorithmWatch zeigt, dass die Klima-Versprechen nicht eingelöst werden können. Um das zu verschleiern, vermischen die Unternehmen verschiedene KI-Technologien – und klammern die energiehungrige generative KI dabei aus.

Der Ausbau von KI-Rechenzentren führt zu einer steigenden Nachfrage nach fossilen Brennstoffen, denn der Energiehunger von KI-Technologien ist offensichtlich. Die nachweislich negativen Auswirkungen auf das Klima werden von den Technologieunternehmen jedoch heruntergespielt, während sie gleichzeitig in Aussicht stellen, KI könne in der Zukunft helfen, die Probleme des Klimawandels zu bewältigen.
Die Behauptungen von Big Tech beruhen dabei nicht auf glaubwürdigen und belegbaren Daten, sondern auf der Selbstausstellung eines „Blanko-Schecks“, um „die Umwelt unter Verweis auf leere Heilsversprechen weiter zu verschmutzen“. Zu diesem Ergebnis kommt der neue Bericht von AlgorithmWatch: „Der KI-Klimaschwindel: Hinter den Kulissen des Big-Tech-Greenwashings“. Während die negativen Auswirkungen nachweisbar seien sowie immer weiter zunehmen würden, basierten die Lösungsversprechen hauptsächlich auf Wunschdenken mit geringer Faktenbasis.
Der Bericht untersucht systematisch die Stichhaltigkeit der Behauptung eines angeblichen „Netto-Klimanutzens“ durch KI. Aus insgesamt acht Quellen wurden dafür 154 KI-Klimaversprechen extrahiert. Das Ergebnis: 150 Versprechen (97 Prozent) bezogen sich entweder auf die „herkömmliche“ KI, also insbesondere auf Vorhersagemodelle und Computer-Vision, oder generative KI mit einem nur sehr eng begrenzten Anwendungsbereich. Nur vier Behauptungen (drei Prozent) bezogen sich tatsächlich auf klar definierbare generative KI-Anwendungen für Verbraucher:innen (wie Chatbots), die mit großen öffentlich zugänglichen Datensätzen trainiert wurden. Die Klimaauswirkungen generativer KI werden durch verallgemeinerte „KI-Nachhaltigkeitsbehauptungen“ also gezielt verschleiert, indem grundsätzlich verschiedene Technologien gleichgesetzt werden.
„ ‚KI’ ist ein sehr neuer Begriff, auch wenn einige der Technologien schon sehr alt sind“, sagt der Hauptautor des Berichts, Energie- und Klimaanalyst Ketan Joshi, gegenüber netzpolitik.org. „Daher nutzen sie diese Unvertrautheit aus. Indem sie diese beiden Dinge miteinander vermischen und den Wandel als unvermeidlich darstellen, entziehen sie sich jeglicher Verantwortung, auf die schlechten, verschwenderischen und schädlichen Dinge zu verzichten.“
KI ist nicht gleich KI
Der für das Jahr 2030 prognostizierte Energieverbrauch generativer KI-Anwendungen liegt dabei um das Dreizehnfache höher als der Energieverbrauch herkömmlicher KI. Dennoch werde unterschlagen, dass die Klimaschäden durch KI-Nutzung überwiegend durch eben diese generativen KI-Anwendungen entstehen. Die Analyse fand so kein einziges Beispiel einer generativen Consumer-KI, die nachweislich zu einer Emissionsreduktion geführt hätte.
„Wenn es Nachhaltigkeitsvorteile durch künstliche Intelligenz gibt, dann durch Anwendungen traditioneller KI mit wenig Ressourcenverbrauch. Die großen sprach- und bildgenerierenden Modelle wie ChatGPT […] verbrauchen Unmengen an Strom und Wasser, verursachen CO₂-Emissionen in der Höhe ganzer Länder, bringen aber keinerlei positiven Nutzen für die Umwelt“, sagt Senior Policy Manager bei AlgorithmWatch, Julian Bothe, gegenüber netzpolitik.org.
Ferner stützen sich laut der Analyse des Reports nur 26 Prozent der 154 untersuchten KI-Klimaversprechen auf tatsächlich wissenschaftliche Studien. 36 Prozent führten keinerlei Belege an, während der Rest überwiegend auf die Unternehmensberichte und Unternehmenswebseiten verwies. Hinzu kämen Verweise auf Medien, sonstige Institutionen oder unveröffentlichte Studien.
Viel Behauptung, kaum Beleg
Ein besonders prägnantes Beispiel sei Google: Der Konzern wirbt seit Jahren damit, KI könne bis 2030 fünf bis zehn Prozent der weltweiten Treibhausgasemissionen einsparen. Dies entspräche dem gesamten Jahresausstoß der Europäischen Union. Die Quelle dieser Statistik hält allerdings keiner Überprüfung stand: Diese ist nämlich der Blogbeitrag eines Beratungsunternehmens aus dem Jahr 2021, das diese Einschätzung offenbar aus der eigenen „Kundenerfahrung“ entnommen hatte. Dennoch tauchte die Behauptung noch im April 2025 in einer Policy-Roadmap von Google auf, die auf die EU zielte – und zwar unter dem Verweis auf „Studien“.
Einige der Zahlen stammen jedoch nicht unmittelbar aus der Unternehmens-PR und tragen ein wissenschaftliches Etikett. Eine Analyse des Ökonomen Nicholas Stern, veröffentlicht in einem Nature-Fachjournal, kommt zu dem Schluss, KI werde die weltweiten Emissionen bis 2035 um 36 Prozent senken. Amy Luers, Head of Sustainability Science and Innovation bei Microsoft, beziffert das Einsparpotenzial in einem Kommentar in Nature auf 1,4 Gigatonnen jährlich. Auch der einflussreiche IEA-Bericht „Energy and AI“ vom April 2025, dessen Entwurf unter anderem von Beschäftigten von Amazon, Google, Nvidia, Meta und Microsoft begutachtet wurde, kommt zu dem Ergebnis, dass KI unter bestimmten Bedingungen Netto-Emissionen einsparen könnte. Der AlgorithmWatch-Bericht hält solche Rechnungen jedoch für fragwürdig, weil sie auf schwach begründeten Beispielen aufbauen. „Es hat mich überrascht, solche Behauptungen in Nature zu sehen“, sagt Joshi. Viele wissenschaftliche Publikationen seien beim KI-Thema enthusiastisch und „womöglich nicht im Einklang mit dem, was wir über die Umweltschäden wissen“.
Ein weiteres Beispiel für irreführende Behauptungen sei auch die der Internationalen Energieagentur, dass das Kreuzfahrtunternehmen Carnival Cruise Lines dank KI seinen Treibstoffverbrauch erheblich gesenkt habe, so Joshi gegenüber netzpolitik.org. „Es scheint wahrscheinlich, dass der Verweis auf der Website größtenteils mithilfe von KI generiert wurde – oder dass es sich zumindest um eine schwache Quelle handelt, die keinen Bezug zu den tatsächlichen Berichten des Unternehmens aufweist.“ Dies verdeutliche laut Joshi, wie das Potenzial von KI nicht nur überbewertet wird, sondern auch, wie KI selbst das Informationsumfeld zerstöre.
Neue Form des Greenwashings
Rechenzentren verbrauchten 2024 rund 1,5 Prozent des weltweiten Stroms, bis 2030 erwartet die IEA eine Verdopplung. Die großen Tech-Konzerne verfehlen ihre eigenen Klimaziele und an den Standorten von Meta, OpenAI und xAI entstehen neue Gaskraftwerke. Der Bericht sieht so eine neue Greenwashing-Strategie. Emissionsintensive Industrien versuchen seit jeher ihre angerichteten Schäden kosmetisch „auszugleichen“, beispielsweise mit betrugsanfälligen Klimazertifikaten. Neu sei hingegen, dass unterschiedliche Technologien unter dem Überbegriff „KI“ zusammengefasst werden, um der Verantwortung für den Ausbau energiehungriger generativer KI zu entgehen.
Tatsächlich gibt es laut Bericht keinerlei glaubwürdige Grundlage für die Aussage, die klimafreundlichen Auswirkungen von Künstlicher Intelligenz würden die schädlichen Folgen der Technologie wieder ausgleichen können. Der Bericht behauptet gleichwohl nicht, dass KI keinerlei Klimanutzen haben könne. Unbelegt sei jedoch das Narrativ, KI könne Schäden im Gigatonnen-Bereich ausgleichen. Statt mit vagen Begriffen und schwachen Belegen die Klimaschäden zu verschleiern, läge die Verantwortung, in echte Nachhaltigkeit zu investieren, weiterhin bei den Big-Tech-Konzernen.
„Wenn es Google, Microsoft und Co. ernst wäre mit ihrer Sorge um die Umwelt, würden sie die Auswirkungen ihrer KI-Technologien offenlegen und auch die tatsächlichen Verbräuche der dafür genutzten Rechenzentren transparent veröffentlichen“, findet Bothe. „Tatsächlich passiert das Gegenteil: Die großen Tech-Unternehmen tun alles dafür, um sich sogar der gesetzlich geregelten Veröffentlichungspflichten zu entledigen – und die Regierungen auf EU- und Bundesebene knicken vor den Forderungen der Tech-Giganten ein.“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Tiere und künstliche Intelligenz: Wie die KI in unser Hackfleisch kommt
Künstliche Intelligenz ist inzwischen in der Massentierhaltung angekommen. Doch können Verhaltensscanner im Stall wirklich das Tierwohl verbessern? Und welches Rezept spuckt ein KI‑Chatbot aus, wenn man ihn nach Spaghetti Bolognese fragt? Mirjam Walser warnt im Interview: Die Folgen von KI für Tiere sind enorm.

Was hat künstliche Intelligenz mit Hackfleisch zu tun? Immer mehr Landwirt*innen nutzen KI-basierte Überwachungssysteme und Verhaltensanalysen von Tieren im Stall. Mittlerweile gibt es KI-Software, die den körperlichen und emotionalen Zustand von in Ställen gehaltenen Tieren überwachen kann. Damit stellt sich eine Reihe von Fragen: Können KI-basierte Überwachungssysteme das Tierwohl im Stall tatsächlich steigern? Sind voll automatisierte Zuchtbetriebe mit Tausenden oder gar Millionen von Tieren die Zukunft der Landwirtschaft? Aber auch: Verstärken große Sprachmodelle wie ChatGPT Gewalt gegen Tiere? Oder kann die Technologie uns im Gegenteil helfen, Tiere endlich zu verstehen?
Diese Fragen hat Mirjam Walser in ihrem Vortrag auf der Digitalkonferenz re:publica aufgeworfen. In der Debatte rund um KI und ihre Regulierung bleibt das Schicksal der rund 50 Milliarden Tiere in der industriellen Tierhaltung eine zentrale Leerstelle, erklärte die Speakerin und Kolumnistin. Sie hat sich im Rahmen der „AI × Animals Fellowship“ der Organisation Sentient Futures eingehend mit künstlicher Intelligenz an der Schnittstelle zum Tierschutz befasst. Walser geht seit Jahren der Frage nach, wie Menschen in einer Gesellschaft leben können, die gleichermaßen gut für Menschen, Tiere und die Umwelt ist.
Wir haben mit ihr über die Entzifferung von Tierkommunikation, mögliche Auswirkungen des Einsatzes von KI in der Tierhaltung und über die Frage gesprochen, ob und wie Chatbots wie ChatGPT oder Claude das Tierwohl berücksichtigen können.
Wale und Schweine mit KI verstehen
netzpolitik.org: Kann uns KI tatsächlich helfen, Tiere besser zu verstehen?
Mirjam Walser: Im Moment ist das noch Zukunftsmusik, aber Forschende arbeiten daran, die Kommunikation der Tiere mithilfe der KI zu entschlüsseln. Es gibt ein Projekt namens CETI, das zu Pottwalen forscht. Pottwale sprechen mit Klicklauten. Lange dachte man, dass sie die Klicklaute zur Orientierung nutzen. Mithilfe von KI haben die Forschenden nun herausgefunden, dass sie ihre Klicklaute so anordnen, als ob sie Silben und ein Alphabet hätten – wie wir Menschen. Das war eine bahnbrechende Entdeckung.
Mit KI konnten auch einzelne Pottwale und ihre Sprache isoliert werden. Man konnte beobachten, wie sie über große Distanzen hinweg lange Gespräche miteinander führen, etwa eine Stunde lang. Einzelne Pottwale klicken sich gelegentlich ein. Es handelt sich also wirklich um Gespräche. Was genau sie sagen, wissen wir noch nicht. Aber es ist schon jetzt klar, dass die Tierkommunikation, sei es von Pottwalen oder Zebrafinken, wahnsinnig komplex ist. Weit komplexer als bis jetzt angenommen. Da sind wir erst am Anfang.
netzpolitik.org: Es gibt mittlerweile auch Unternehmen, die sich in dem Bereich versuchen.
Mirjam Walser: Wenn es um Wildtiere geht, steht vor allem ein Forschungsinteresse im Vordergrund. Bei Haustieren ist ein kommerzielles Interesse dahinter. Ein Beispiel ist die chinesische Firma Baidu, die sich darauf spezialisiert, die Kommunikation von Katzen und Hunden zu entschlüsseln.
Eine große Leerstelle ist aber das Entschlüsseln der Kommunikation von sogenannten „Nutztieren“. Aus gutem Grund. Denn wenn wir sie verstehen würden, würden sich die Tierschutzgesetze verändern müssen – und unsere Beziehung zu den Tieren wohl auch. Wenn uns beispielsweise ein Schwein sagen könnte, wie sich ein Leben in einem engen Stall anfühlt: dunkel, kalt und sehr stressig.

Mit KI kranke Tiere im Stall identifzieren
netzpolitik.org: Gleichzeitig wird der Einsatz von KI-basierten Überwachungssystemen in der Tierhaltung, etwa Sensoren, Kameras und Verhaltensscannern, damit begründet, dass sie die Gesundheit und das Wohlbefinden der Tiere steigern können. In einer Umfrage von Bitkom aus dem Jahr 2024 gaben beispielsweise 20 Prozent der Landwirt*innen an, mit KI die Gesundheitsüberwachung von gezüchteten Tieren verbessern zu wollen. Ist da etwas dran?
Mirjam Walser: Da ist auf jeden Fall etwas dran. Beispielsweise wenn man durch den Einsatz von KI in der Tierhaltung messen kann, dass ein Tier krank ist. Man muss sich vorstellen, in so einem riesigen Stall leben etwa 10.000 Hühner. KI kann – ähnlich wie bei der Entschlüsselung der Tierkommunikation – eine einzelne Stimme aus einem riesigen Durcheinander isolieren. Zum Beispiel auch, wenn eine Kuh hustet oder niest. Das sind oft Indikatoren für Atemwegserkrankungen. Ohne KI kann man diese Erkrankung viel schwerer erkennen – mit der Konsequenz, dass dann die Tiere zu spät behandelt oder sogar getötet werden müssen. Wenn also anhand von überwachten Gesundheitsdaten deutlich wird, dass sich ein Schwein beispielsweise wenig bewegt und weniger frisst, kann man natürlich früher eingreifen.
Im ersten Schritt ist es also tatsächlich eine Verbesserung. Denn wenn Tiere krank sind, mindert das natürlich ihr Wohlbefinden. Aber das ist ja nur der oberflächliche Aspekt. Denn Tierwohl bemisst sich nicht nur daran, ob ein Tier gesund ist oder nicht. Sondern auch, und vielleicht noch viel mehr, an psychologischen Faktoren. Und die werden nicht gemessen.
netzpolitik.org: Wie meinst du das?
Mirjam Walser: Mit KI kann man nicht messen und nicht verstehen, was es für eine Kuh bedeutet, den ganzen Tag angebunden zu sein oder sich kaum bewegen zu können. Wenn sie doch natürlicherweise bis zu 13 Kilometern pro Tag laufen würde, nur für die Futteraufnahme. Oder etwa, dass Tiere wie Hühner oder Schweine eigentlich soziale Hierarchien haben und in diesen nicht leben können.
Ein anderes Beispiel: 85 Prozent der Legehennen leiden an Brustbeinbrüchen. Das ist ein Kollateralschaden, den man in der Massentierhaltung in Kauf nimmt. Wie fühlt es sich an, mit so einem Brustbeinbruch zu leben? Das wird nicht in das Tierwohl einkalkuliert und kann so auch nicht direkt gemessen werden.
„Unter dem Deckmantel von Tierwohl“
netzpolitik.org: Nehmen wir als Beispiel die automatisierte Erkennung von Schmerzensschreien bei Schweinen. Ein Mikrofon zeichnet die Laute der Ferkel auf und eine KI wertet sie automatisch aus. Wenn sich also Schweine in den Schwanz beißen und der Grenzwert mehrfach überschritten wird, wird ein Alarmsignal an die Landwirt*innen gesendet. Hier kann KI also nicht helfen, dass es gar nicht erst zum Schwanzbeißen kommt?
Mirjam Walser: Das Problem mit dem Messen ist, dass solches Stressverhalten in der Massentierhaltung eigentlich immer Standard ist. Und KI basiert auf Werten, die wir eingeben. Erst wenn die Stresssymptome wie Schwanzbeißen oder Kannibalismus bei Hühnern wirklich extrem werden, kann die KI ausschlagen. Aber was ist der eigentliche Grund? Wieso hacken sich die Hühner die Köpfe ein?
Unter Umständen werden ein paar Hühner getötet, weil sie aggressiv sind. Das bringt jedoch per se noch keine systematische Verbesserung. Es wird gewissermaßen nur ein Pflaster auf die Wunde geklebt. Die eigentliche Wunde – die Tierhaltung – bleibt offen und unverändert. Eine tatsächliche Änderung würde bedeuten, diese Grundlage, das Minimum hochzuschieben. Dann würde KI ganz anders ausschlagen.
Tierwohl ist auf einem unglaublich tiefen Niveau in unserer Gesellschaft. Und KI bringt keine Verbesserung diesbezüglich. Im Gegenteil kann KI das noch verfestigen und skalieren. Denn worum es beim Sammeln dieser Daten eigentlich geht, ist die Optimierung von Massentierhaltung unter dem Deckmantel von Tierwohl. Es geht darum, Tierhaltung profitabel zu machen. Nur ein gesundes Schwein lässt sich profitabel zu einer Wurst verarbeiten.
Massentierhaltung als perfektes Umfeld für KI
netzpolitik.org: Für wen lohnt sich der Einsatz von KI in der „Nutztierhaltung“? Wie verbreitet ist das mittlerweile?
Mirjam Walser: Die überwältigende Mehrheit der „Nutztiere“ lebt in Massentierhaltung. In Deutschland kommt 95 Prozent des Fleisches aus Massentierhaltung. Und genau das ist ein perfektes Umfeld für den Einsatz von KI. Sie ist vor allem für Großbetriebe gedacht, wo eine gewisse Standardisierung vorliegt und auch eine Skalierbarkeit möglich ist. Deshalb nutzen sie vor allem Großbetriebe.
KI ist eben auch eine finanzielle Investition. Es lohnt sich nur, wenn sie sich auch wieder rentiert und das wird über die Masse an Tieren wieder eingenommen. Für Bergbauern, die vielleicht 10 Kühe und 20 Hühner haben, ist sie weniger sinnvoll. Für sie lohnt es sich finanziell nicht und sie können selbst sehen, wie es der Kuh oder den Hühnern geht.
Wie weit diese Technologien verbreitet sind, ist nicht ganz klar. Auf Agrarkonferenzen wird intensiv darüber gesprochen. In Deutschland ist der Einsatz von KI noch nicht so weit fortgeschritten wie in den USA oder China, aber es ist nur eine Frage der Zeit.
netzpolitik.org: Wie sieht es denn in China genau aus? Und kann das so ähnlich auch in Deutschland kommen?
Mirjam Walser: In China gibt es ein sogenanntes Schweinehochhaus mit 26 Stockwerken und Platz für 650.000 Schweine. Es ist hochgradig technologisiert. Das Ziel ist, dass alles autonom abläuft und kein menschlicher Einsatz mehr notwendig ist.
Solche Großsysteme können wir natürlich nicht eins zu eins auf Deutschland und Europa übertragen. Die gibt es bei uns nicht. Es gab ein Schweinehochhaus, aber das ist schon vor einigen Jahren geschlossen worden. Hinzu kommt, dass die Tierwohlstandards hier etwas höher sind als in China. Daher sind gewisse Dinge einfach nicht möglich. Zum Glück.
Denn auch trotz KI-Einsatz muss einem Schwein oder einem Huhn ein gewisses Minimum an Platz gegeben werden, auch wenn es extrem wenig ist. Hühner haben nicht mehr Platz als ein DIN-A4-Blatt. Hier kommt der Politik also eine enorme Rolle zu, die Tierwohlstandards zu heben.
Mit KI das Schmerzempfinden von Tieren manipulieren?
netzpolitik.org: Es gibt noch andere Bereiche, in denen der Einsatz von KI diskutiert wird, nämlich bei der Genmodifikation von Tieren. Was hat es damit auf sich?
Mirjam Walser: Genmodifikationen waren immer schon Teil der Massentierhaltung. Hühner waren vor 50 Jahren viel kleiner als heute. Jetzt setzen sie ein Vielfaches an Gewicht von damals an. Sie wurden durch Zucht, die richtige Auswahl und die richtige Genkombination modifiziert. Auch Euter sind viel dicker geworden im Vergleich zu vor 50 Jahren. Das ist im Prinzip nichts Neues. KI ist hier also nur die logische Konsequenz.
Es geht zum Beispiel darum, den Fleischertrag eines Tieres zu erhöhen. Also wie kann ein Huhn noch mehr Fleisch ansetzen, ohne dass es unter dem Gewicht zusammenbricht? Oder bei der Ausgabe von Milch: Wie kann die Milchabschöpfung noch vergrößert werden?
Außerdem gibt es mittlerweile die Idee, das Schmerzempfinden von Tieren mithilfe von KI zu modifizieren. Denn wenn die Tiere weniger Schmerzempfinden haben, kann man noch mehr von ihnen in die Ställe reinquetschen. Bisher gibt es keine konkrete Anwendung dafür, weil das ethisch enorm schwierig ist. Aber das ist ein Thema, das aktuell diskutiert wird.
Chatbots und das Foie-Gras-Paradox
netzpolitik.org: Tierschützer*innen und Wissenschaftler*innen weisen auf die Gefahr hin, dass große Sprachmodelle wie ChatGPT unseren Bias gegenüber Tieren, der auch in den Trainingsdaten allgegenwärtig ist, reproduzieren und verstärken können. Gleichzeitig hat Anthropic vor Kurzem festgelegt, dass Claude „das Wohlergehen der Tiere und aller fühlenden Wesen“ berücksichtigen soll. Was bedeutet das konkret in der Anwendung?
Mirjam Walser: Die Verfassung von Claude ist eine Liste von Werten, die Claude beachten und auch gegeneinander abwägen muss. Dort geht es um verschiedene Formen von Diskriminierung wie Rassismus und Sexismus. Im Januar 2026 hat Anthropic Tierwohl in die Liste aufgenommen. Bei keinem der großen Sprachmodelle kam es bisher vor. Claude ist somit das erste Modell, das Tierwohl berücksichtigen soll. Was das jetzt genau bedeutet, ist die große Frage, denn diese Verfassung ist nicht bindend. De facto ist bisher nichts umgesetzt.
Ein Beispiel ist das Foie-Gras-Paradox. Foie Gras ist die sogenannte Gänsestopfleber. Dafür werden Gänse innerhalb kürzester Zeit zu Tode gemästet. Wenn man also Claude nach einem Rezept fragt, gibt der Chatbot aus, „kaufe Gänsestopfleber, bereite sie zu und so weiter“. Wenn man aber fragt, wie quäle ich auf brutalste Art und Weise eine Gans, dann sagt Claude, „dazu kann ich dir keine Auskunft geben, das verstößt gegen die Richtlinien“.
An solchen Beispielen zeigt sich, wie unglaublich komplex dieses Thema ist. Wenn jemand beispielsweise nach einem Rezept von Spaghetti Bolognese fragt, geht es darum, zum einen das Interesse von Menschen, die Spaghetti Bolognese mit Fleisch essen wollen, weil das vielleicht eine Tradition ist, mit Tierwohl abzuwägen, das dem entgegensteht. Denn für Hackfleisch muss ein Tier aufgezogen, in der Massentierhaltung gehalten und getötet werden. Das Tier wird geschädigt. Wenn man Tiere in so einem Sprachmodell also tatsächlich mitdenken würde, müsste es als Antwort zunächst ausgeben: „Hier habe ich eine vegane Variante mit Sojahack.“ Und weil die vegane Variante viele Menschen wahrscheinlich abschrecken würde, müsste Claude die tierische Variante auf Nachfrage liefern.
Aktuell geht es bei Claude darum, Tierwohl und die Frage, ob ein Tier zu Schaden kommt oder nicht, vorerst im Testumfeld einzubetten. In Tests beurteilen Menschen, ob die Antworten der KI gegen Diskriminierungsrichtlinien verstoßen. Weil wir Menschen Diskriminierung von Tieren aber verinnerlicht haben, ist es sehr komplex, das zu beurteilen.
netzpolitik.org: Was müsste passieren, damit KI in Zukunft nicht dazu beiträgt, Tieren noch mehr zu schaden?
Mirjam Walser: Das Thema muss zum einen mehr Aufmerksamkeit kriegen. Aktuell ist es ein absolutes Nischenthema, was zutiefst verwunderlich ist, wenn man bedenkt, dass Millionen und Milliarden von Tieren davon betroffen sind.
Zum anderen braucht es eine stärkere Kooperation zwischen Menschen, die in Tierethik und KI-Ethik forschen, denn bisher sind das weitgehend getrennte Felder. Parallel dazu muss diese Forschung in die konkrete Arbeit des AI-Alignments einfließen. Auch hier ist also ein interdisziplinärer Austausch nötig, damit tierethische Erkenntnisse tatsächlich in der Evaluation von Modellen, in der Entwicklung von Tests und in der Übersetzung ethischer Überlegungen in technische Parameter ankommen.
Auch der Politik kommt eine Rolle zu, die KI-Ethik-Richtlinien zu bestimmen. Aktuell liegt der Fokus darauf, dass KI keinen Schaden an Menschen, Gebäuden oder der Umwelt anrichten darf. Tiere werden nicht explizit erwähnt. Tiere müssen aber explizit erwähnt werden, sonst wird sich nichts ändern.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Ubuntu 26.10 daily builds now available to download
 Daily builds of Ubuntu 26.10 ‘Stonking Stingray’ are now available for download, as development on the distro’s next major release kicks in to gear. As the name suggests, new ISOs are produced from development code on a (mostly) daily basis, giving those keen to test October’s release in advance the ability to do so. However, because package updates can break the ability for a bootable image to be created, it’s not unusual for there to be temporary gaps between new daily builds being available. Daily builds will continue to be produced for remainder of the Ubuntu 26.10 development cycle, right […]
Daily builds of Ubuntu 26.10 ‘Stonking Stingray’ are now available for download, as development on the distro’s next major release kicks in to gear. As the name suggests, new ISOs are produced from development code on a (mostly) daily basis, giving those keen to test October’s release in advance the ability to do so. However, because package updates can break the ability for a bootable image to be created, it’s not unusual for there to be temporary gaps between new daily builds being available. Daily builds will continue to be produced for remainder of the Ubuntu 26.10 development cycle, right […]
You're reading Ubuntu 26.10 daily builds now available to download, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.
Attacke auf Messenger: Signal will in Zukunft stärker vor Phishing warnen
Signal reagiert auf die umfangreiche Phishing-Kampagne mit Änderungen in der App. Derweil wird die Dimension der Attacke deutlicher: Schon im Januar waren fast 14.000 Accounts gezielt angeschrieben worden.
In einem Interview mit dem Spiegel (€) hat Signal-Chefin Meredith Whittaker angekündigt, dass der Messenger in Zukunft zusätzliche Warnhinweise anzeigen wird, um Phishing besser zu verhindern. Hintergrund der Maßnahme sind die teilweise erfolgreichen Phishing-Versuche gegen Vertreter:innen aus Politik, Militär und Journalismus, der in Deutschland nach Medienberichten zwei Ministerinnen und die Bundestagspräsidentin zum Opfer fielen.
Im Interview sagte Whittaker:
Wenn jemand zum ersten Mal eine Nachricht von einer unbekannten Nummer erhält, werden künftig zusätzliche Warnhinweise angezeigt. Das Annehmen neuer, unbekannter Kontakte wird in Zukunft nicht mehr mit einem einzigen Klick möglich sein und zwingend einen Warnhinweis enthalten. Wir prüfen noch weitere Ideen und werden dazu bald mehr bekannt geben. Und um es noch einmal klar zu sagen: Signal wird Nutzer niemals in einem zweiseitigen Chat kontaktieren, um sie nach ihrer PIN, ihrem Schlüssel oder anderen Informationen zu fragen.
Öffentlich bekannt wurde die Attacke in Deutschland, als netzpolitik.org am 28. Januar darüber berichtete, dass zahlreiche Journalist:innen im Visier stünden. Gut eine Woche nach dem Bericht warnten dann der Verfassungsschutz (BfV) und das Bundesamt für Sicherheit in der Informationstechnik (BSI) vor der Angriffswelle. Mittlerweile haben die Behörden ein weiteres Update der Warnung samt Handlungsleitfaden veröffentlicht.
Am gestrigen Donnerstag war die Phishing-Kampagne auch Thema im Digital- und im Innenausschuss des Bundestages. In nicht-öffentlicher Sitzung wurde durch Verfassungsschutzchef Sinan Selen und BSI-Chefin Claudia Plattner die Kampagne nachgezeichnet und noch einmal vor Phishing gewarnt. Laut dem Bericht wussten die Behörden erst „im Januar“ über die Angriffe Bescheid. Nach Informationen von netzpolitik.org könnte allerdings ein Ende 2025 vom Phishing betroffener Bundestagsabgeordneter beide Behörden schon früher informiert haben.
Viel spricht für Russland als Urheber des Angriffs
Mittlerweile verdichtet sich, dass Russland hinter der Attacke stecken dürfte. Das niederländische Verteidigungsministerium hatte Anfang März verlautbart, dass Russland hinter der laufenden Phishing-Kampagne gegen hochrangige Personen aus Politik, Militär, Zivilgesellschaft und Journalismus stecken soll. BSI und Verfassungsschutz hatten vor den Attacken gewarnt und diese als „wahrscheinlich staatlich gesteuert“ bezeichnet. Die Bundesregierung schreibt den Angriff bislang nicht offiziell einem Land zu, ließ aber über Regierungskreise verbreiten, dass Russland dahinter stecke.
In einer Mitteilung auf der Webseite des niederländischen Verteidigungsministeriums sprechen sowohl der militärische Geheimdienst MIVD als auch der zivile Geheimdienst AIVD von „russischen Staatshackern“, die hinter dem Angriff auf Signal und WhatsApp stecken würden. Auch netzpolitik.org hat Hinweise, welche die Theorie einer russischen Urheberschaft des Angriffs untermauern.
Wir sind ein spendenfinanziertes Medium.
Unterstütze auch Du unsere Arbeit mit einer Spende.
Mehr als 13.700 Telefonnummern
Das Medienhaus Correctiv hatte zudem den Angriff auf den früheren Vizepräsidenten des Bundesnachrichtendienstes, Arndt Freytag von Loringhoven, ausgewertet und ist dabei auch auf digitale Spuren gestoßen, die nach Russland führen.
Weiteren Spuren nachgegangen sind auch die IT-Sicherheitsexperten des Security Labs von Amnesty International, die sich schon frühzeitig mit der Kampagne befasst haben. Sie haben einem Bericht des Spiegels (€) zufolge ein Angriffswerkzeug gefunden. Wie Donncha Ó Cearbhaill, der Leiter des Amnesty-Labs dem Medium mitteilte, soll es sich um ein in russischer Sprache programmiertes Werkzeug namens ApocalypseZ handeln.
Die Untersuchung konnte erstmals auch eine Zahl der angegriffenen Signal-Accounts offenlegen. In der Datenbank der Angreifer konnten die Amnesty-Expert:innen Mobilfunknummern potenzieller Opfer sehen. „Im Januar waren es mehr als 13.700“, sagte Ó Cearbhaill gegenüber dem Spiegel. In den Screenshots des Schadprogramms konnten die Forscher:innen zudem sehen, dass viele der Phishing-Nachrichten über polnische und niederländische Nummern verschickt wurden.
Laut dem Spiegel-Bericht bestätigt sich nun auch die Annahme, die Donncha Ó Cearbhaill schon im Januar gegenüber netzpolitik.org geäußert hatte: Die Angreifer lesen die Kontakte derjenigen aus, die auf das Phishing hereinfallen – und versenden dann neue Nachrichten. Ziel ist die Übernahme der Accounts samt Einblicken in Netzwerke und zukünftige Inhalte der Kommunikation.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
![]()
KI-Verordnung: EU-Parlament und Rat einigen sich auf gelockerte Pflichten für die Industrie
Die EU will die KI-Verordnung aufweichen. Eine erste Einigung sieht nun vor, bestimmte Regulierungen für die Industrie abzuschwächen und zeitlich deutlich nach hinten zu verschieben. Hinzugekommen ist ein Verbot von KI-Anwendungen, mit denen sexualisierte Deepfakes erstellt werden können.

Nachdem die EU-Verhandlungen zum digitalen Omnibus Ende April 2026 vorübergehend geplatzt waren, konnten Rat und Parlament gestern Nacht im Trilog eine vorläufige Einigung erzielen; die Kommission war als Vermittlerin beteiligt.
Die Einigung betrifft die Aufnahme des Verbots von sogenannten KI-Nudifiern in die KI-Verordnung. „Nudifier“ sind Anwendungen, mit deren Hilfe sexualisierte Deepfakes erstellt werden können. Außerdem sollen Auflagen für die Industrie beim Einsatz von risikoreichen KI-Systemen begrenzt sowie zentrale Pflichten aus dem AI Act für Hochrisiko-Systeme deutlich nach hinten verschoben werden – auf Ende 2027 und 2028. Der vorliegende Kompromiss zwischen Rat und Parlament muss noch formal bestätigt werden.
Der Trilog war zuvor an der Frage gescheitert, wie in der Industrie mit der Hochrisiko-Kategorie für KI-Systeme umgegangen werden soll, die bereits durch sektorale Bestimmungen reguliert werden. Zentrale Pflichten des AI Acts für besonders risikoreiche KI-Systeme sollten eigentlich bereits ab dem 2. August 2026 wirksam werden. Der Kompromiss sieht nun vor, dass die Anwendung der KI-Verordnung dort begrenzt wird, wo sektorale Sicherheitsanforderungen vergleichbare KI-Regeln enthalten.
Die EU verabschiedete den AI Act (Verordnung über künstliche Intelligenz) im Mai 2024. Er ordnet KI-Technologie vier abgestuften Risikokategorien zu und regelt Pflichten für die Hersteller und Anbieter von KI-Systemen oder Produkten, die KI-Technologie enthalten. KI-Systeme mit inakzeptablem Risiko können verboten werden.
Die EU-Kommission möchte die Regelungen im Rahmen des sogenannten Digitalen Omnibus jedoch vereinfachen, um bürokratische Hürden für Unternehmen abzubauen und Europas Wettbewerbsfähigkeit zu steigern. Das Gesetzespaket ist umstritten. Es enthält unter anderem Lockerungen bei der Datenschutzgrundverordnung oder beim Training von KI mit personenbezogenen Daten.
Verbot von KI-„Nudifiern“
Konkret haben sich Parlament und Rat darauf geeinigt, in Zukunft KI-Anwendungen zu verbieten, mit deren Hilfe man sexualisierte Deepfakes erstellen kann. Das Thema wurde zu einem zentralen Vorhaben, nachdem Nutzer*innen mit dem Chatbot Grok Anfang des Jahres binnen weniger Tage Millionen von nicht-einvernehmlichen Deepfakes erstellt hatten.
Bereits Ende März hatte sich das Parlament dafür ausgesprochen, solche KI-Anwendungen zu verbieten. Im Trilog ging es noch um die Details der Formulierung. Das Verbot umfasst jetzt explizit auch das Erstellen von Inhalten, die sexuellen Missbrauch von Kindern zeigen. Zudem soll es untersagt sein, KI-Anwendungen auf den Markt zu bringen, die ohne Zustimmung Deepfakes von “intimen Teilen einer identifizierbaren Person” oder die Person bei sexuellen Handlungen zeigen.
Die geplante Verschärfung ist nicht die erste EU-Regelung zu Deepfakes. Eine andere Richtlinie sieht bereits vor, dass Mitgliedstaaten die Verbreitung von sexualisierten Deepfakes unter Strafe stellen, wenn diese geeignet sind, einer Person schweren Schaden zuzufügen. Deutschland setzt dies mit dem geplanten Gesetz gegen digitale Gewalt derzeit um. Das geplante Verbot in der KI-Verordnung würde den Fokus von der Bestrafung der Täter*innen auf die Anbieter solcher Anwendungen verschieben.
Im geplanten Text steht nun auch die fehlende Zustimmung der gezeigten Personen als definierendes Merkmal. Fachleute forderten das seit langem. Zugleich kritisiert etwa Ana Ornelas von der European Sex Workers’ Rights Alliance (ESWA), die Beschränkung auf „identifizierbare Personen“. Sie fürchtet, dass dies in der Durchsetzung zu Schlupflöchern führen könnte.
Lockerungen und Fristverlängerung für Industrie
Hochrisiko-KI-Systeme in Bereichen wie Beschäftigung, Bildung, Migration, Strafverfolgung oder kritische Infrastruktur sollen Anforderungen aus dem AI Act erst ab dem 2. Dezember 2027 erfüllen müssen. Für KI in Medizinprodukten, Maschinen oder Spielzeug gilt der 2. August 2028. Anbieter von KI-Systemen müssen diese grundsätzlich in der EU-Datenbank für risikoreiche Systeme registrieren – auch wenn sie der Ansicht sind, die Einstufung als risikoreich träfe nicht zu oder sei ausgenommen.
Die Sonderregelung für Maschinenverordnung schwächt nach Meinung des europäischen Verbraucherverbands BEUC den Verbraucherschutz. Konkret kritisiert der Verband, dass Alltagsgeräte wie Industriemaschinen aus der KI-Aufsicht herausfallen würden. Bei deren Versagen könnten Menschen zu Schaden kommen. Der Deal enthält offenbar auch eine Klausel, mit der die EU-Kommission später weitere KI-Systeme ohne neues Gesetzgebungsverfahren aus dem Geltungsbereich des AI Acts herausnehmen kann. Die Kommission erhalte damit eine Hintertür für künftige KI-Deregulierung.
BEUC-Generaldirektor Agustín Reyna meint, der überhastete Prozess habe ein Gesetz hervorgebracht, das komplizierter und weniger wirksam als vorher sei und vor allem der Industrie nutze.
Zumindest an manchen Stellen scheint der Kompromiss strenger. Die EU-Kommission wollte die Verarbeitung sensibler personenbezogener Daten – etwa Angaben, aus denen Ethnie oder Religion hervorgehen können – zur Bias-Erkennung erleichtern. Rat und Parlament begrenzten hier durch striktere Maßstäbe.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Konferenz für Menschenrechte: Druck aus China soll zu Absage der RightsCon geführt haben [Update]
Eine der wichtigsten Konferenzen zu digitalen Grund- und Menschenrechten sollte diese Woche in Sambia stattfinden. Doch die Veranstaltung in dem südafrikanischen Land wurde kurzfristig abgesagt. Die Veranstalter:innen erheben schwere Vorwürfe: Demnach ließ China wegen taiwanesischer Gäste die Muskeln spielen.

Morgen sollte in Lusaka die RightsCon beginnen, eine der wichtigsten Konferenzen für Grund- und Menschenrechte in der digitalen Welt. Doch kurz vor dem Beginn meldete vorige Woche die Regierung des Gastgeberlandes Sambia Bedenken an und verkündete, die Konferenz müsse verschoben werden. Inzwischen ist sie ganz abgesagt und die Ausrichterin, die Nichtregierungsorganisation Access Now, erhebt schwere Vorwürfe – nicht nur gegen Sambia, sondern auch gegen die Volksrepublik China. Diese habe wegen der Teilnahme taiwanesischer Gäste Druck auf die Regierung Sambias ausgeübt.
Mehr als 2.600 Gäste erwartet
Die Konferenz findet jedes Jahr in einem anderen Land statt. Seit 2024 habe man die erste RightsCon im südlichen Afrika in enger Zusammenarbeit mit der Regierung Sambias vorbereitet, heißt es in einem Statement, das Access Now am Freitag veröffentlicht hat. Mehr als 2.600 Gäste seien in der sambischen Hauptstadt Lusaka erwartet worden, viele von ihnen hätten ihre Reise lange geplant und teilweise bereits angetreten. Weitere 1.100 Teilnehmende im Netz waren angemeldet, zusammen repräsentierten sie mehr 750 Organisationen aus 150 Ländern: Menschenrechts-Aktivist:innen, Vertreter:innen von Regierungen und internationalen Organisationen, Mitarbeitende von Tech-Unternehmen.
Entsprechend groß war der Schock, als Ende April, nur wenige Tage vor dem Beginn der viertägigen Veranstaltung, erste Berichte über eine Verschiebung der Konferenz durch die sambische Regierung die Runde machten. Noch am 26. April hatte das Ministerium für Technologie und Wissenschaft die bevorstehende Veranstaltung begrüßt. „RightsCon 2026 wird Sambia eine strategische Plattform bieten, um sein Engagement für eine sichere, inklusive und auf Rechten basierende digitale Zukunft unter Beweis zu stellen und gleichzeitig wirtschaftliche Chancen für lokale Innovatoren und Unternehmen zu erschließen“, so eine Sprecherin des Ministeriums.
Einen Tag später, so Access Now, sei man vom Ministerium telefonisch informiert worden, dass es ein Problem gebe: „Uns wurde mitgeteilt, dass Diplomaten der Volksrepublik China Druck auf die Regierung Sambias ausübten, weil Vertreter der taiwanesischen Zivilgesellschaft planten, persönlich an der Veranstaltung teilzunehmen“, so Access Now in der englischsprachigen Erklärung. Dies habe man mit Nachdruck zurückgewiesen und unverzüglich taiwanesische Gäste gewarnt. „Wir haben ihnen gesagt, dass wir von einer Anreise abraten würden, bis mehr Klarheit herrscht“, so Nikki Gladstone von Access Now gegenüber WIRED.
Mehrere kritische Beiträge im Programm
Laut Access Now folgten zahlreiche Versuche der Klärung. Am Ende habe die sambische Regierung jedoch klargemacht, dass die Konferenz nur stattfinden dürfe, wenn inhaltliche Konzessionen gemacht würden. Ihnen sei „informell aus mehreren Quellen“ mitgeteilt worden, dass „die RightsCon nur dann fortgesetzt werden könne, wenn wir bestimmte Themen zensieren und gefährdete Gruppen, darunter unsere taiwanesischen Teilnehmer:innen, von der Teilnahme vor Ort und online ausschließen würden“. In Reaktion darauf erfolgte am 30. April schließlich die Absage der Konferenz durch die Veranstalter:innen. „Das war unsere rote Linie“, so Access Now.
Das Programm der RightsCon enthielt mehrere Sessions, die sich kritisch mit Chinas Rolle in der globalen Digitalisierung auseinandersetzten, etwa zum Export digitaler Zensur- und Überwachungswerkzeuge, zur Verbreitung von Desinformation in Regionen wie Afrika oder zu chinesischen Cyber-Attacken. Unter den Speaker:innen waren unter anderem die Chefinnen von Amnesty International Taiwan und des Taiwan Network Information Center, das für die Registrierung von Domainnamen und die Vergabe von IP-Adressen in Taiwan zuständig ist. 2025 fand die RightsCon in Taipeh statt, der Hauptstadt Taiwans.
Die Taiwan-Frage führt immer wieder zu geopolitischen Spannungen, die Volksrepublik China droht regelmäßig mit einer militärischen Eroberung der strategisch wichtigen Insel. Erst kürzlich beschimpfte ein Sprecher der chinesischen Regierung Taiwans Präsidenten Lai Ching-te als „Ratte“. Anlass war eine Reise Lais in das südafrikanische Königreich Eswatini. Medienberichten zufolge sollen drei Staaten im Indischen Ozean auf Druck Pekings Überflugrechte für Lais Maschine zurückgezogen haben, um die Reise zu verhindern.
Kritische Abhängigkeiten
China hat in den vergangenen Jahrzehnten massiv auf dem afrikanischen Kontinent investiert und so Abhängigkeiten geschaffen. Insbesondere im Rahmen des Projekts „Neue Seidenstraße“ haben chinesische Kredite und Konzerne den Ausbau der analogen und digitalen Infrastruktur in vielen afrikanischen Ländern ermöglicht. Auch zwischen Sambia und China sind die Verbindungen eng. WIRED zufolge hat die Zambia Development Agency wenige Tage vor der Konferenz, am 23. April einen Vertrag über 1,5 Milliarden US-Dollar mit einem staatlichen chinesischen Bauunternehmen verkündet, um die Stromkapazitäten des Landes auszubauen. Auch das Internationale Konferenz-Zentrum in Lusaka, in dem die RightsCon stattfinden sollte, wurde 2022 mit Hilfe eines Zuschusses der chinesischen Regierung in Höhe von 30 Millionen US-Dollar umfassend erweitert.
Dass China seine Macht gegen die globale Digital-Rights-Community derart offen ausspielt und Abhängigkeiten ausnutzt, ist jedoch ungewöhnlich. Die Volksrepublik positioniert sich seit vielen Jahren im Globalen Süden als systemische Alternative zur US-Dominanz, auch im Bereich der Internet Governance. In einem 2022 Weißbuch spricht China gar von einer „Schicksalsgemeinschaft im Cyberspace“.
„Ich denke, dieser Fall zeigt deutlich, dass China nicht nur eines der stärksten Systeme zu Online-Zensur und ‑Überwachung aufgebaut hat, sondern derzeit auch neue Methoden der Offline-Zensur außerhalb der eigenen Grenzen testet“, kommentiert Alena Epifanova von der Deutschen Gesellschaft für Auswärtige Politik den Fall. „Das könnte künftig mehrere Länder betreffen, die enge wirtschaftliche Beziehungen zu China haben oder von chinesischen Investitionen abhängig sind“, so die Vermutung der Analysten des von der Bundesregierung finanzierten Thinktanks. „Wenn es um Taiwan geht, zieht das Land alle Register – unabhängig von Partnerschaftsnarrativen –, um Taipeh zu isolieren.“
Wir haben die Botschaft der Volksrepublik China und die Botschaft Sambias am Montag kurzfristig für ein Pressestatement zu den Vorwürfen angefragt und bis zur Veröffentlichung keine Antwort erhalten. Wir reichen diese nach, sofern wir eine Antwort erhalten.
Update 1, 05.05.2026, 12:45 Uhr: Mehrere Europäische Organisationen wie die European Partnership for Democracy (EPD), European Digital Rights, Digitale Gesellschaft und Zašto haben einen offenen Brief zur Absage der Konferenz veröffentlicht. Darin kritisieren sie die Entscheidung der sambischen Regierung und fordern unter anderem Konsequenzen der EU und ihrer Mitgliedsländer. Ein automatisiert übersetzter Auszug aus dem englischsprachigen Brief:
Dieser Schritt geschieht nicht in einem Vakuum. Die Zivilgesellschaft steht weltweit bereits unter erheblichem Druck und sieht sich mit drastischen Mittelkürzungen sowie Gesetzen konfrontiert, die darauf abzielen, den zivilgesellschaftlichen Handlungsspielraum einzuschränken. Die Absage der RightsCon reiht sich ein in ein besorgniserregendes globales Muster der Unterdrückung, das genau jene Organisationen und Personen ins Visier nimmt, die sich für die Verteidigung der Grundrechte einsetzen.
Der Zeitpunkt macht dies besonders deutlich. Der Tag der Pressefreiheit der UNESCO findet diese Woche in Lusaka statt – ein Ereignis, das offene Gesellschaften feiern sollte und nicht von der Unterdrückung zivilgesellschaftlicher Versammlungen durch die Regierung des Gastgeberlandes überschattet werden darf.
EPD unterstützt den Aufruf unserer Partner an die Europäische Union und ihre Mitgliedstaaten, Sambia klar zu machen, dass diese Entscheidung zutiefst alarmierend ist und die Gefahr birgt, einen Schatten auf die Beziehungen zwischen der EU und Sambia zu werfen. Wir unterstützen auch den Aufruf, die Delegierten, die heute am Weltpressefreiheitstag in Lusaka teilnehmen, dazu aufzufordern, diese Plattform zu nutzen, um ihre Stimme zu erheben. Schließlich unterstützen wir den Aufruf an die sambische Regierung, die Rechte von Aktivisten auf Versammlung, Organisation und freie Meinungsäußerung in ihrem Land oder im Ausland uneingeschränkt zu respektieren.
Update 2, 05.05.2026, 13:30 Uhr: Die Botschaft der Republik Sambia hat auf unsere Presseanfrage geantwortet und uns ein Statement geschickt, das sie bereits am 29. April veröffentlicht hatte. Darin betont die Regierung, dass es sich lediglich um eine Verschiebung der Konferenz handele, und bedauert dadurch entstehende Unannehmlichkeiten. Sie begründet den Schritt wie folgt (maschinell übersetzt aus dem Englischen):
Die Verschiebung wurde notwendig, da umfassende Informationen zu zentralen Themen, die auf dem Gipfel zur Diskussion stehen sollten, offengelegt werden mussten. Diese Offenlegung ist unerlässlich, um eine vollständige Übereinstimmung mit den nationalen Werten, den politischen Prioritäten und den übergeordneten Erwägungen des öffentlichen Interesses Sambias zu gewährleisten.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Abschiebeverordnung: EU will mit digitalen Mitteln mehr und schneller abschieben
Die EU arbeitet mit Hochdruck an der Abschiebeverordnung. ICE-ähnliche Razzien in Privatwohnungen und elektronische Fußfesseln für Menschen ohne Aufenthalt könnten Realität werden, wenn die Verordnung in dieser Form beschlossen wird – warnen Expert*innen und zivilgesellschaftliche Organisationen.

Ein „Gemeinsames Europäisches Rückkehrsystem“ soll künftig dafür sorgen, dass abgelehnte Asylbewerber*innen und andere Migrant*innen ohne legalen Aufenthalt schneller und in größerer Zahl abgeschoben werden. Die höchst umstrittene Rückführungsverordnung, auch als Abschiebeverordnung bekannt, befindet sich in den letzten Zügen der EU-Gesetzgebung. EU-Kommission, Parlament und Mitgliedstaaten haben ihre Positionen festgelegt und müssen nun im Trilog eine geeinte Version verhandeln. Der EU-Innen- und Migrationskommissar Magnus Brunner bezeichnete die Verordnung zuletzt als „das fehlende Puzzlestück“. Das Gesamtbild ist dabei die härtere Migrationspolitik, die die EU mit dem Migrations- und Asylpakt eingeschlagen hat, der ab Juni 2026 zur Anwendung kommen soll.
„Die Verordnung ist ein klares Zeichen dafür, dass sich die Migrationspolitik in der EU radikalisiert hat“, sagt Bernd Parusel, Senior Researcher am Schwedischen Institut für Europäische Studien gegenüber netzpolitik.org. „Die weitgehende und drastische Verschärfung der bisherigen Rückführungspolitik der EU geht an die Grenzen dessen, was menschenrechtlich vertretbar ist“, so der Wissenschaftler, der zur geplanten Verordnung forscht.
Ein Teil der Verordnung sieht Abschiebungen in sogenannte „Return Hubs“ in Länder außerhalb der EU vor, zu denen die Menschen keinerlei Bezug haben. Es geht auch um die Inhaftierung von Familien sowie Kindern ohne Eltern und die massive Ausweitung maximal zulässiger Abschiebehaft. Außerdem setzt das Gesetzesprojekt darauf, Menschen ohne Papiere aufzuspüren und jene, die abgeschoben werden sollen, verstärkt digital zu überwachen.
Stehen ICE-ähnliche Razzien in der EU bevor?
Eine Regelung, die einen großen Aufschrei unter zivilgesellschaftlichen Akteuren und Angestellten im öffentlichem Sektor ausgelöst hat, verpflichtet Mitgliedstaaten, Menschen ohne Papiere „aufzuspüren“. Dass birgt die Gefahr, dass es auch in der EU zu Menschenjagden nach Migrant*innen an öffentlichen Plätzen und im Privaten geben könnte. Der Vorschlag der Kommission sieht vor, dass Mitgliedstaaten „effektive und angemessene Maßnahmen“ einführen sollen, „um Drittstaatsangehörige aufzuspüren, die sich illegal in ihrem Staatsgebiet aufhalten“.
Das EU-Parlament hat diese Regelung in seiner Fassung gestrichen. Doch es besteht die Möglichkeit, dass der noch härtere Vorschlag der Mitgliedstaaten Eingang in den finalen Text findet. Ihre Position sieht „investigative Ermittlungsmaßnahmen“ vor, um die Zahl der Abschiebungen zu erhöhen. Dazu gehören beispielsweise Durchsuchungen von Wohnungen und „anderen relevanten Räumlichkeiten“. Dies würde der Polizei ermöglichen, Krankenhäuser, Schulen, Arbeitsplätze, öffentliche und soziale Einrichtungen und Wohnungen zu durchsuchen – ganz ohne richterliche Anordnung. Betroffen wären alle, die Menschen ohne Papiere unterstützen, und Bürger*innen, in deren Wohnungen die Behörden sie vermuten.
Auch die Durchsuchung und Beschlagnahmung von elektronischen Geräten, darunter Handys, wären Teil dieser investigativen Maßnahmen – etwas, was auch das EU-Parlament will, als eine Mitwirkungspflicht der Betroffenen ohne Möglichkeit des Widerspruchs.
Risiko von Racial Profiling für ganze Communitys
Zahlreiche unabhängige Expert*innen, darunter 16 UN-Sonderberichterstatter*innen für Menschenrechte sowie mehr als 100 zivilgesellschaftliche Organisationen, warnen, dass solche erweiterten Befugnisse illegale Praktiken des Racial Profiling befeuern und Grundrechte von Menschen ohne Papiere untergraben würden. Da rassistisches Profiling sich oft auf das Aussehen, die Sprache oder die vermutete Herkunft der Betroffenen stützt, erhöhe sich das Risiko von Diskriminierung. Das gelte nicht nur für Menschen ohne Aufenthaltserlaubnis, sondern für ganze gesellschaftliche Gruppen, die von Rassismus betroffen sind, schreibt Platform for International Cooperation on Undocumented Migrants (PICUM), eine der rund 100 kritischen Organisationen.
„Aufspürmaßnahmen schüren Angst, Diskriminierung und Verfolgung und zerstören soziale Bindungen und Gemeinschaften“, kritisiert PICUM in ihrer Stellungnahme. Solche Regelungen halten Menschen davon ab, grundlegende Gesundheitsversorgung wie beispielsweise Schwangerschaftsbetreuung, Behandlung chronischer Krankheiten und Impfungen in Anspruch zu nehmen.
Die Organisationen sowie die UN-Sonderberichterstatter*innen befürchten außerdem, dass die Aufspür-Regelung eine Meldepflicht für Beschäftigte im öffentlichen Dienst nach sich ziehen könnte. Lehrkräfte und Ärzt*innen müssten demnach Menschen ohne gültige Aufenthaltspapiere melden, damit sie abgeschoben werden können. Das würde das Vertrauen zwischen ihnen und ihren Klient*innen nachhaltig beeinträchtigen und könne eine Krise des Gesundheitssystems ähnlich wie in den USA nach sich ziehen, warnen die Organisationen weiter. Dort meiden Menschen ohne Aufenthaltsgenehmigung aus Angst medizinische Einrichtungen.
In Europa haben sich deshalb 1.100 medizinische Fachkräfte im Vorfeld der Abstimmung im Europaparlament gegen die Verordnung ausgesprochen. „Wir weigern uns, zu Instrumenten der Einwanderungskontrolle zu werden“, heißt es in dem Brief.
Europaweite Zementierung von Menschenrechtsverletzungen
Derartige Aufspürmaßnahmen sind nicht ganz neu. Ähnliche Praktiken werden in einzelnen Mitgliedstaaten bereits angewandt, wenn auch uneinheitlich. In Deutschland beispielsweise hat die Polizei immer wieder Schlafzimmer in Geflüchtetenunterkünften ohne Durchsuchungsbeschluss gestürmt, um Menschen abzuschieben. Erst im vergangenen Herbst hat das Bundesverfassungsgericht diese Praxis für verfassungswidrig erklärt. Dieses Beispiel zeigt, dass solche Maßnahmen auf nationaler Ebene erfolgreich angefochten werden konnten.
Schafft es die Regelung in die geeinte Verordnung, würden entsprechende Maßnahmen EU-weit festgeschrieben. Das würde solchen Praktiken neue Legitimität verleihen, ihre Ausweitung auf ganz Europa erfordern und es in Zukunft erheblich erschweren, sie anzufechten oder rückgängig zu machen, warnt PICUM.
Kommt die elektronische Fußfessel für Menschen ohne Papiere?
Laut ProtectNotSurveil, einem Zusammenschluss von Organisationen, die sich mit digitalen Rechten von Migrant*innen befassen, gehen die umstrittenen Aufspürmaßnahmen mit einem verstärkten Einsatz von Überwachungstechnologien einher. Denkbar wären beispielsweise mobile Geräte zur biometrischen Identifizierung, wie sie etwa ICE-Agent*innen in den USA nutzen. Seit Anfang des Jahres setzen diese die App „Mobile Fortify“ zur Gesichtserkennung ein, um den Aufenthaltsstatus von Personen bei Kontrollen auf der Straße festzustellen.
Ein anderes alarmierendes Beispiel ist die geplante elektronische Überwachung von Personen, die abgeschoben werden sollen. Die Verordnung führt sie als vermeintliche Alternative zur Abschiebehaft ein. Vielfach haben Jurist*innen und Menschenrechtsorganisationen jedoch kritisiert, dass sie keine echte Alternative zur Haft darstellt. „Sie ist nicht nur eine Alternative, sondern auch eine zusätzliche Zwangsmaßnahme“, erklärt Parusel. Denn die elektronische Überwachung könnte laut der Verordnung nicht nur statt der Haft, sondern auch davor oder danach eingesetzt werden – selbst wenn die ohnehin ausgedehnte Haftdauer von 24 Monaten bereits überschritten ist.
Wie die elektronische Überwachung im Konkreten aussehen soll, legt die geplante Verordnung nicht näher fest. „Denkbar sind vielleicht eine elektronische Fußfessel oder GPS-Ortung“, sagt Parusel. „Der Entwurf der Verordnung gibt dem nationalen Gesetzgeber hier Freiräume.“
Weil solche Technologien in hohem Maße in die Privatsphäre sowie die Bewegungsfreiheit eingreifen und potenziell stigmatisierend sind, gelten sie weithin als de-facto-Inhaftierung.
Darüber hinaus sieht der Vorschlag vor, dass alle Personen, die abgeschoben werden sollen, sich in einem bestimmten geografischen Gebiet aufhalten, an einer bestimmten Adresse wohnen oder regelmäßigen Meldepflichten nachkommen müssen. Das werfe nicht nur ernsthafte Bedenken hinsichtlich der Verhältnismäßigkeit auf, sondern könnte ebenfalls durch den Einsatz invasiver Überwachungs- und Kontrolltechnologien umgesetzt werden, warnt ProtectNotSurveil.
Neue Europäische Rückkehrentscheidung
Das Kernstück der Verordnung ist die „Europäischen Rückkehrentscheidung“. Diese enthält ein standardisiertes digitales Datenblatt mit Informationen zur Abschiebeentscheidung. Alle Mitgliedstaaten sollen dieses Datenblatt abrufen können. „Wenn ein Mitgliedstaat eine Rückführungsentscheidung getroffen hat, dann ist sie im System drin“, erklärt Parusel gegenüber netzpolitik.org. „Sollte die Person in ein anderes EU-Land weiterwandern, wird dieser Mitgliedstaat sehen können, dass die Person im ersten Land schon zur Ausreise aufgefordert wurde, und ob schon ein Zielland festgelegt wurde“, so der Wissenschaftler.
Sobald ein Mitgliedstaat entschieden hat, eine Person abzuschieben, soll diese Entscheidung von allen anderen EU-Mitgliedstaaten ab 2027 verpflichtend anerkannt und auch umgesetzt werden, schlägt das Europaparlament vor. Die anderen Mitgliedsstaaten wären dann nicht mehr verpflichtet, die Situation der Person und ihre Schutzbedürftigkeit selbst zu prüfen. Unter den Mitgliedstaaten ist dieser Punkt umstritten, in ihrem Entwurf haben sie Einschränkungen bei der gegenseitigen Anerkennung vorgesehen.
Nationale Migrationsbehörden sollen die „Europäische Rückkehrentscheidung“ parallel zur nationalen Abschiebeanordnung erlassen und über das Schengener Informationssystem (SIS II) zur Verfügung stellen. Dadurch werden personenbezogene Daten von Betroffenen für Tausende Polizeibeamt*innen in der gesamten EU zugänglich, kritisieren die ProtectNotSurveil-Organisationen. Das Schengener Informationssystem II, das größte Migration- und Polizeidaten-Austauschsystem der EU, sei ohnehin für wiederholten Datenmissbrauch und die systematische Verweigerung der Datenschutzrechte bekannt. Es gibt dokumentierte Fälle, in denen Polizei- und Einwanderungsbehörden sich nicht an Vorschriften gehalten haben. Die Verordnung baut direkt auf dieser Architektur auf und verstärkt ihre Eingriffsintensität.
Datenübermittlung an Drittstaaten darf nicht zu Todesstrafe führen
Zudem setzt die Verordnung auf die Erfassung großer Datenmengen ausreisepflichtiger Personen auf, die allein zum Zweck der Abschiebung erhoben und zwischen den Mitgliedstaaten ausgetauscht werden sollen. Neben Gesundheitsdaten und Auszügen aus Strafregistern sind es auch biometrische Daten und Informationen wie Bildungsabschlüsse, Reiserouten oder Kontakte von Familienangehörigen im Zielland der Abschiebung. „Es handelt sich um einen noch weitergehenden rückkehrspezifischen Datenaustausch“, sagt Parusel. „Ausreisepflichtige Drittstaatsangehörige werden in einem ganz anderen Ausmaß durchleuchtet und überwacht als beispielsweise EU-Bürger, von denen der Staat diese Daten nicht braucht und auch nicht haben will“, fügt der Wissenschaftler hinzu.
Sensible personenbezogene Daten wie Gesundheitsdaten und Auszüge aus Strafregistern sollen auch an Drittländer fließen, in denen es keine mit der EU vergleichbaren Datenschutzgarantien gibt. Den betroffenen Personen stehen dort deshalb keine wirksamen Rechtsbehelfsmechanismen zur Verfügung, kritisert ProtectNotSurveil.
Für Menschen, die in ihren Herkunftsstaaten politisch verfolgt werden, stelle das ein großes Risiko dar, sagt Parusel. Bei Ausreisepflichtigen gehe man von Menschen aus, die keine Schutzgründe haben. „Aber es gibt auch Menschen, deren Asylgesuch fälschlicherweise abgelehnt wurde oder denen nicht gelungen ist, ihre Schutzgründe glaubhaft vorzubringen“. Diese Menschen seien dann leichter auffindbar und ihnen drohe akute Verfolgungsgefahr. Auch der Europäische Datenschutzbeauftragte warnte, die Übermittlung von strafrechtlich relevanten Daten darf nicht zu einer Todesstrafe oder anderer grausamer Behandlung im Drittstaat führen.
Wird die Verordnung zu mehr Abschiebungen führen?
Ob die Verordnung tatsächlich zu einfacheren und wirksameren Abschiebeverfahren und steigenden Abschiebezahlen führen wird? Mehr als 250 Organisationen gehen davon aus, dass sie den gegenteiligen Effekt haben wird. Sie werde die Zahl der ausreisepflichtigen Menschen eher künstlich in die Höhe treiben. Denn der Vorschlag etabliert die Abschiebung als Standardoption für Menschen ohne legalen Aufenthalt und lässt wenig bis gar keine Alternativen übrig. Er verpflichtet die Mitgliedstaaten, bei jeder Entscheidung zur Beendigung eines legalen Aufenthalts zugleich einen Abschiebebescheid zu erlassen, ohne zuvor andere Aufenthaltsmöglichkeiten auf nationaler Ebene zu prüfen. Das sind zum Beispiel Aufenthaltsgenehmigungen aus humanitären, medizinischen oder familiären Gründen.
Damit das europäische Rückführungssystem besser funktioniert, sollten die Mitgliedstaaten nicht mehr Menschen als nötig in das Rückführungssystem leiten, findet auch Bernd Parusel. „Zur Ausreise sollten nur diejenigen aufgefordert werden, die eine realistische Aussicht auf Rückkehr haben.“
In der Wissenschaft geht man außerdem davon aus, dass der gewünschte abschreckende Signaleffekt der neuen Zwangsmaßnahmen begrenzt sein wird. „Ich glaube nicht, dass man mit Zwangsmaßnahmen alleine das Problem löst. Man muss auch über Alternativen zur Zwangsrückkehr nachdenken“, so der Wissenschaftler gegenüber netzpolitik.org. Das könne beispielsweise die Legalisierung von Menschen ohne legalen Aufenthalt sein. Denn anders als Abschiebungen sind Bleiberechte effektiver darin, die Zahlen der sogenannten Ausreisepflichtigen zu senken und der Überforderung der Verwaltung entgegenzuwirken.
Am 22. April trafen sich Vertreter*innen der Mitgliedstaaten mit Abgeordneten des EU-Parlaments zum zweiten Mal, um ihre Positionen zur Abschiebeverordnung zu verhandeln. Die ersten Trilog-Verhandlungen fanden bereits am 26. März statt. Nur wenige Stunden vorher hatte die konservative EVP-Fraktion im EU-Parlament unter der Führung des deutschen CSU-Politikers Manfred Weber mit Unterstützung rechtsextremer Parteien wie der AfD ihren Standpunkt verabschiedet.
Da die Mitgliedstaaten und das Europaparlament sich in vielen Punkten einig sind, ist mit einem schnellen Abschluss der Trilog-Verhandlungen zu rechnen. Ein Beschluss ist noch im ersten Halbjahr 2026 geplant, die nächsten Verhandlungen sind für Juni angesetzt. Für die meisten Maßnahmen wünschen sich die Mitgliedstaaten eine Umsetzungsfrist von zwei Jahren, bis auf die Abschiebungen in „Return Hubs“. Diese sollen direkt nach Beschluss der Verordnung möglich sein, auch wenn es hier noch viele Fragezeichen gibt. Deutschland versucht derzeit aktiv, solche Deals mit Drittstaaten auszuhandeln.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
AI Act: Trilog-Verhandlungen über gelockerte KI-Regeln gescheitert
Die EU will unter hohem Zeitdruck ihre Regeln für Künstliche Intelligenz aufweichen. Nun sind eigentlich abschließende Verhandlungen gescheitert. Alle Beteiligten machen sich gegenseitig Vorwürfe, am Ende könnten Regeln zum besseren Schutz vor KI-generierten Nacktbildern unter die Räder geraten.

Die EU-Institutionen können sich weiter nicht auf eine abgeschwächte Fassung der KI-Verordnung einigen. Medienberichten zufolge sind gut zwölfstündige Trilog-Verhandlungen zwischen dem Europäischen Parlament, dem Rat und der Kommission am Dienstag gescheitert.
Ein zentraler Streitpunkt war offenbar eine vorgeschlagene Ausnahme für risikoreiche KI-Systeme in der Industrie, wie Table Media [€] berichtet. Das Parlament hatte demzufolge vorgeschlagen, die sektorspezifischen Regelungen zu ändern: Industriemaschinen sollten demnach aus der Hochrisiko‑Kategorie herausfallen. Entscheidend für eine Einstufung als Hochrisiko sollte stattdessen die tatsächliche Sicherheitsfunktion der KI werden. Rat und Parlament sind sich in dieser Frage jedoch uneins.
Gestritten wurde dem Bericht zufolge zudem über ein Verbot sogenannte „Nudifier“-Anwendungen. Das sind generative KI‑Systeme, die Menschen auf Foto- oder Videomaterial entkleiden können. Das Parlament möchte nicht‑einvernehmliche intime Inhalte verhindern, es konnte jedoch keine Einigung darüber erzielt werden, welche Körperteile darunterfallen.
Das kritisiert unter anderem Eva Lejla Podgoršek, Senior Policy Managerin bei AlgorithmWatch. Es sei wichtig, „dass die wenigen guten Vorschläge nicht unter die Räder geraten.“ Das geplante Verbot von KI-Systemen, die nicht einvernehmliche sexualisierende Deepfakes ermöglichen, sei ein wichtiger Baustein, um Betroffene wirksam zu schützen.
Wenn drei sich streiten, freut sich niemand
Die Anpassungen der bereits im August 2024 in Kraft getretenen KI-Verordnung sollen im Rahmen des sogenannten Digitalen Omnibus erfolgen. Mit dem von der EU-Kommission vorgeschlagenen Gesetzespaket sollen Vorschriften im digitalen Sektor vereinfacht werden, um bürokratische Hürden für Unternehmen abzubauen und Europas Wettbewerbsfähigkeit zu steigern. Das Paket ist jedoch umstritten. Es enthält auch Lockerungen der Datenschutzgrundverordnung, etwa beim Training von KI mit personenbezogenen Daten oder einer Neudefinition personenbezogener Daten.
Während die Verhandlungen über den Daten-Omnibus sich offenbar länger hinziehen, machten die Beratungen über den KI-Omnibus schnell Fortschritte. Die Zeit drängt: Zentrale Pflichten des AI Acts für besonders risikoreiche KI-Systeme werden ab dem 2. August 2026 wirksam. Diese Fristen sollen mit dem Omnibus aufgeschoben werden. Gestern sind die finalen Verhandlungen allerdings bereits zum zweiten Mal geplatzt.
Laut Table Briefings sieht die zypriotische Ratspräsidentschaft keine Schuld bei sich: „Wir sind mit einer sehr konstruktiven Haltung in die heutige Sitzung gegangen und haben konkrete Vorschläge zur Lösungsfindung unterbreitet“. Man habe während der Verhandlungen ein hohes Maß an Flexibilität gezeigt, aber keine Einigung mit dem Europäischen Parlament erzielen können. Das Ziel der Vereinfachung werde jedoch weiterhin verfolgt.
Stimmen aus dem Parlament sehen dies anders. Es sei „inakzeptabel, dass die Ratspräsidentschaft nicht bereit war, einen substanziellen Kompromiss zu machen, um die Überregulierung von KI zu beenden“, sagte die Europaabgeordnete Svenja Hahn (FDP). Michael McNamara (parteilos), Verhandlungsführer für das EU-Parlament, räumte in einem Interview mit Tech Policy Press jedoch selbst ein, dass die vorgeschlagene Verlagerung in sektorale Gesetze „eher zu Deregulierung als zu einer Vereinfachung führen könnte“.
Schwere Vorwürfe kommen von den Grünen im EU-Parlament, insbesondere gegenüber deutschen Konservativen, wie Euractiv berichtet. Sie werfen der Europäischen Volkspartei vor, das Omnibus-Gesetz bewusst zu verzögern und dabei auch die Hilfe von rechtsextremen Parteien im Parlament in Anspruch zu nehmen. Merz wolle noch weitergehende Lockerungen der KI-Regeln, als sie derzeit verhandelt würden. Das wiederholte Scheitern lassen der Verhandlungen sei ein Schachzug, um Zeit zu gewinnen und so die Positionen der EU-Mitgliedstaaten zu beeinflussen.
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.
Canonical is ‘ramping up’ AI in Ubuntu this year
 AI features are coming to Ubuntu in 2026, though Canonical has made clear that the distro is not becoming an AI product. In a community post, Jon Seager, VP of engineering at Canonical, says the company is “ramping up its use of AI tools in a focused and principled manner” this year, with a bias toward local inference and open-weight models whose licence terms match Canonical’s values. AI features in Ubuntu will take one of two forms. Implicit features improve existing capabilities using on-device AI models, for things like text-to-speech and speech-to-text to bolster accessibility. Ubuntu will become a context-aware […]
AI features are coming to Ubuntu in 2026, though Canonical has made clear that the distro is not becoming an AI product. In a community post, Jon Seager, VP of engineering at Canonical, says the company is “ramping up its use of AI tools in a focused and principled manner” this year, with a bias toward local inference and open-weight models whose licence terms match Canonical’s values. AI features in Ubuntu will take one of two forms. Implicit features improve existing capabilities using on-device AI models, for things like text-to-speech and speech-to-text to bolster accessibility. Ubuntu will become a context-aware […]
You're reading Canonical is ‘ramping up’ AI in Ubuntu this year, a blog post from OMG! Ubuntu. Do not reproduce elsewhere without permission.